Ans: v1 = character(0) v2 = numeric(0) v3 = logical(0).
xx <- list(name="Alice", gender="F", age=11)How do you access the items in a list by index?
Ans: xx[[1]], xx[[2]], xx[[3]]
Here is an interactive session:
> xx <- list(name="Alice", gender="M", age=11) > xx $name [1] "Alice" $gender [1] "M" $age [1] 11 > print(xx[[1]]) [1] "Alice" > print(xx$name) [1] "Alice"
num letter 1 1 A num letter 1 2 B ... num letter 1 26 ZAns: Here is the script (improved from the one given in class):
biglist <- NULL
for(i in 1:26) {
biglist[[i]] <- data.frame(num=i,
letter=rawToChar(as.raw(64+i)))
}
print(biglist)
myConcat <- function(u, v) {
lenu <- length(u)
lenv <- length(v)
w = rep(0, lenu + lenv)
for(i in 1:lenu) {
w[i] = u[i]
}
for(i in 1:lenv) {
w[i + lenu] = v[i]
}
return(w)
}
runTimings <- function( ) {
df <- data.frame(size=numeric(0),
fast=numeric(0), slow=numeric(0))
for(n in seq(50000, 250000, 50000)) {
u = runif(n)
v = runif(n)
times <- system.time(c(u, v))
fast_time = as.vector(times[3])
times <- system.time(myConcat(u, v))
slow_time = as.vector(times[3])
df <- rbind(df, data.frame(size=n,
fast=fast_time, slow=slow_time))
}
return(df)
}
kids <- read.table("c:/datasets/kids1.txt", header=T)
kids[order(kids$name), ]
kids[order(kids$age), ]
kids[order(-kids$age), ]
kids[order(kids$gender, -kids$age, kids$name), ]
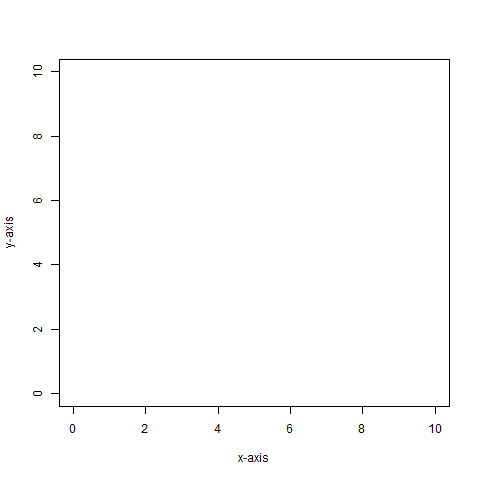{kind=link}
- The points (2, 3), (5, 1), (8, 8) plotted with red plotting symbols
pch=16.
- The polyline defined by (1, 9), (1, 1), (8, 8).
- The string "Start Point" centered at (2, 1).
Ans:
plot(NULL, NULL, xlim=c(0, 10), ylim=c(0, 10), xlab="x-axis", ylab="y-axis") points(c(2, 5, 8), c(3, 1, 8), pch=16, col="red") lines(c(1, 1, 8), c(9, 1, 8)) text(2, 1, "Start Point")
Ans: The str function shows the structure of an object:
> str(kids) 'data.frame': 2 obs. of 3 variables: $ name : Factor w/ 2 levels "Alice","Bob": 1 2 $ gender: Factor w/ 2 levels "F","M": 1 2 $ age : int 11 12The summary function is similar. It summarizes the data in an object:
> summary(kids)
name gender age
Alice:1 F:1 Min. :11.00
Bob :1 M:1 1st Qu.:11.25
Median :11.50
Mean :11.50
3rd Qu.:11.75
Max. :12.00
(function(x)sum(x^2))(1:10)(The normal way to use such a function is like this:
sumOfSquares <- function(x) {
sum(x^2)
}
print(sumOfSquares(1:10))
Give an example of where anonymous functions are useful in R.Ans: The apply function where you apply a function to rows of a matrix or dataframe.
Ans: It means clicking on or mousing over points in a scatterplot to get more information about those points, such as observation numbers, labels, or corresponding points in other plots.
Ans: True. A factor represents categorical data. You can use numbers to represent categorical data.
Use R to compute the 0.63 quartile = Q(0.63) for the vector
v <- c(45, 31, 19, 76, 111)using methods 1 and 4. Verify your results by hand.
Ans: First sort the vector:
19 21 45 76 111Compute the 0.67 quartile = Q(0.67) using Method 1:
We have
| Index: | 1 | 2 | 3 | 4 | 5 |
| Quantile: | 0.2 | 0.4 | 0.6 | 0.8 | 1.0 |
| Value: | x1=19 | x2=21 | x3=45 | x4=76 | x5=111 |
To find the 0.67 quartile, note that 0.67 is between quantile 0.6 and 0.8 in the table--we round up to 0.8, so Q(0.67) = x4 = 76.
Compute Q(0.67) using Method 4:
Using the table above we see that Q(0.6) = x3 = 45 and Q(0.8) = x4 = 76. Use linear interpolation to find Q(0.67)
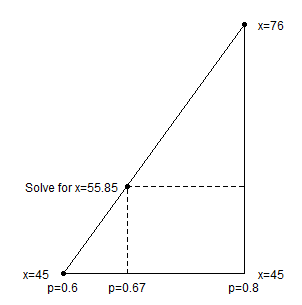
We use similar triangles:
-
(x - 45) / (76 - 45) = (0.67 - 0.6) / (0.8 - 0.6)
(x - 45) / 31 = 0.07 / 0.2
x = 31 * 0.07 / 0.2 + 45 = 55.85
Check with R:
> quantile(v, 0.67, type=1) 67% 76 > quantile(v, 0.67, type=4) 67% 55.85 >Here is the R script that draws the interpolation diagram.
See the Quantile Computations document for the details of computing quantiles of types 1 to 9.