Ans: A normal density with population mean μ=0 and variance σ=1. (Recall that the population (or sample) variance is the population (or sample) standard deviation squared. The standard normal distribution is denoted by N(0, 1). We abbreviate the statement that z is a N(0, 1) random variable as z ∼ N(0, 1).
Ans: A critical point is a point x on a curve where the first derivative f'(x) = 0, that is where the tangent line to the curve is horizontal, and x is a relative minimum or maximum. For a standard normal density, x = 0, the center of the density. This center is also the mean and the median. An inflection point is a point on the curve where the second derivative f"(x) = 0, where the curve changes from concave up to concave down, or vice versa. A normal density has inflection points at x = μ - σ and μ + σ. Thus the population standard deviation σ can be defined as the distance from the critical point to either of the inflection points.
Ans: If the mean μ and standard deviation σ are known for a dataset, compute the z-score of a data point x like this: z = (x - μ) / σ. For example, IQ scores are scaled so that μ = 100 and σ = 15, so the z-score for an IQ score x is computed as
-
z = (x - 100) / 15
If μ and σ are not known, use the sample mean and standard deviation instead to compute the z-score: z = (x - x)/sx. To compute the z-score for one of the sample means in a sequence of repeated experiments, use
-
z = (x - μ) / SEmean
where SEmean = sx / √n
-
[-1, 1] [-2, 2] [-3, 3]
Ans: Use the standard normal tables, which are the two tables in Table A: Standard Normal Probabilities. The first table is for negative z values; the second table is for positive z values. Compute the probability that z is in [-∞, 1] minus the probability that z in in [-∞, -1], which is 0.8413 - 0.1586 = 0.6827. Use similar calculations for [-2, 2] and [-3, 3]. This R session also computes the probabilities:
> pnorm(1) - pnorm(-1)
[1] 0.6826895 #<-- Matches the well
known value 68%.
> pnorm(2) - pnorm(-2)
[1] 0.9544997 #<-- Matches the well
known value 95%.
> pnorm(3) - pnorm(-3)
[1] 0.9973002 #<-- Matches the well
known value 99.7%.
> pnorm(4) - pnorm(-4)
[1] 0.9999367 #<-- Very close to 1.
You can also compute these four probabilities in one line as> pnorm(c(1, 2, 3) - pnorm(c(-1, -2, -3)) [1] 0.6826895 0.9544997 0.9973002Here is how to compute these probabilites using a SAS script:
* The cdf function means cumulative
distribution function;
data probs;
p1 = cdf("normal", 1) - cdf("normal", -1);
output;
p2 = cdf("normal", 2) - cdf("normal", -2);
output;
p3 = cdf("normal", 3) - cdf("normal", -3);
output;
proc print;
run;
Here is the SAS output:
Obs p
1 0.68269
2 0.95450
3 0.99730
Ans: If the probability of a standard normal random variable being in [-z, z] is 0.95, then the probability of being in [-∞, z] is 0.975, because
-
P(z in [-∞, -z]) = P(z in [-∞, -z]) = 0.025),
-
P(z in [-∞, z]) = P(z in [-∞, -z]) + P(z in [z, -z]) = 0.025 + 0.095 = 0.975.
Looking up 0.975 in the body of the standard normal table, we find that the z corresponding to it is z = 1.96, so the 95% confidence interval is [-1.96, 1.96]. This can be computed with R like this:
> qnorm(0.975) [1] 1.959964Similarly we find that a 99% confidence interval for z ∼ N(0, 1) is [-2.58, 2.58].
Use this R script to find the 95 and 99% confidence intervals for z ∼ N(0, 1):
qnorm(c(0.975, 0.995)) Output: [1] 1.959964 2.575829Here is the corresponding SAS script and output:
data confint;
val = quantile("normal", 0.975);
output;
val = quantile("normal", 0.995);
output;
proc print;
run;
Output:
Obs val
1 1.95996
2 2.57583
Ans: The square root of the variance of the mean. It measures how variable the sample mean would be if you repeated the experiment many times. Compute the standard error of the mean with SEmean = sx / √x. See Property 9 in Section 6 of the Properties of Random Variables document for a derivation of the expression for SEmean.
Ans: An outlier is a point that is further than expected from the center of the distribution. The engineer's rule says that an outlier is a point with a z-score greater than 2 or less than -2. An extreme outlier is a point with a z-score greater than 3 or less than -3. A mild outlier is an outlier but is not an extreme outlier. Outliers can also be determined by looking at the boxplot, which was first proposed by John Tukey (1915 to 2000). In this case, an outlier is a point that is outside of the inner fences. where the inner fences are the points 1.5 IQRs below the 25%ile and 1.5 IQRs above the 75%ile.
-
5 39 75 79 85 90 91 93 93 98
See the NIST Example to see how to create boxplots with SAS or R.
Ans: To draw the boxplot, we obtain the following information using the Tukey's Hinges method:
Median = 50%ile = (85 + 90) / 2 = 87.5.
Quartile 1 (Q1) = 25th%ile = Median of bottom half of sorted list = 75.
Quartile 3 (Q3) = 75th%ile = Median of top half of sorted list = 93.
If the sample size is odd, the middle value is used in both the top and bottom halves of the list.
Inner quartile range = IQR = Q3 - Q1 = 93 - 75 = 18.
Now construct the box plot; the bottom, middle, and top horizontal lines are Q1, Q2, and Q3, respectively.
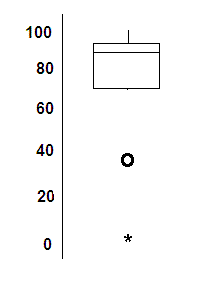
Now determine the inner and outer fences for the purpose of determining the outliers:
The inner fences are located at
Q1 - 1.5 * IQR = 75 - 1.5 * 18 = 48
and Q3 + 1.5 * IQR = 93 - 1.5 * 18 = 120
Any points that are outside of the inner fences are considered to be outliers.
These points are 5 and 39. (There are no outliers above 120.)
The outer fences are located at
Q1 - 3 * IQR = 75 - 3 * 18 = 21
and
Q3 + 3 * IQR = 93 + 3 * 18 = 147
Any points outside of the outer fence are considered to be extreme outliers and are marked with *.
5 is the only extreme outlier.
39 is an outlier, which is not an extreme outlier; it is considered to be a mild outlier and is marked with O.
Normally vertical lines (whiskers) are drawn between Q3 and the lower inner fence, and between Q3 and the upper inner fence, but only if there are data points there. There are no data points between the lower inner fence at 48 and the outlier at 39, so there is no whisker drawn between between 39 and 48.
SAS code for drawing the boxplot:
proc boxplot; plot scores * dummy / boxstyle = schematic;The variable dummy is defined in the data step as 1 or some other arbitrary constant.
R function call for drawing the boxplot:
boxplot(scores)Here are the resulting SAS boxplot and R boxplot. Note that neither SAS nor R distinguishes between mild and extreme outliers. For both boxplots, all outliers are shown with an O symbol.
Ans: Enhanced Editor, Log Window, Results Window (HTML and graphics output), Output Window (typewriter output).
Ans: (Not discussed in class, but you should know how a histogram is constructed.) Here is the histogram:
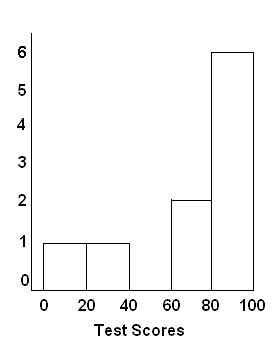
SAS code for drawing the histogram:
proc univariate noprint;
histogram scores / endpoints =
(0, 20, 40, 60, 80, 100);
or
proc univariate noprint;
histogram scores / endpoints =
(0 to 100 by 20);
R function call for drawing the histogram:hist(scores, breaks=seq(0, 100, 20))Here are the resulting SAS histogram and R histogram.
* Create dataset. data kids; infile kids.txt; input name, gender, age, firstobs=2; proc print data=kids proc means mean;The input file is c:\datasets\kids.txt, which contains
Name Gender Age Sally F 12 Alex M 11 Jason M 9 Molly F 10Ans: Here is the corrected version:
* Create dataset; data kids; infile "c:/datasets/kids.txt" firstobs=2; input name $ gender $ age; proc print data=kids; proc means mean; run;
Ans: Select the statements to run in the R script and enter Control-R, or right-click in the script window and select Run line or selection.
kids = read.table("c:/datasets/kids.txt", header=TRUE)
cat("kids data frame:\n")
kids
cat("Average age of kids:\n")
mean(kids$Age)
The R cat function literally outputs text to the console window.
New line characters can be included as \n.
{kind=link}