

Next: Discovery of Aggregate Usage
Up: A Web Mining Framework
Previous: System Architecture
The required high-level tasks in usage data preprocessing are data
cleaning, user identification, session identification, pageview
identification, and path completion. The latter may be necessary due to
client-side or proxy level caching. User identification is
necessary for Web sites that do not use cookies or embedded session
Ids. We use the heuristics proposed in [3] to identify unique
user sessions form anonymous usage data and to infer cached references.
Pageview identification is the task of determining which page
file accesses contribute to a single browser display. Not all pageviews
are relevant for specific mining tasks. Furthermore, among the relevant
pageviews some may be more significant than others. The significance of
a pageview may depend on usage, content and structural characteristics
of the site, as well as prior domain knowledge specified by the site
designer. For example, in an in an e-commerce site pageviews
corresponding to product-oriented events (e.g., shopping cart changes
or product information views) may be considered more significant than
others. In order to provide a flexible framework for a variety of data
mining activities a number of attributes must be recorded with each
pageview. These attributes include the pageview id (normally a URL
uniquely representing the pageview), duration (for a given user
session), static pageview type (e.g., content, navigational, product
view, index page, etc.), and other meta-data.
Transaction identification can be performed as a final
preprocessing step prior to pattern discovery in order to focus on the
relevant subsets of pageviews in each user session [3]. The
transaction file can be further filtered by removing very low support
or very high support pageview references (i.e., references to those
pageviews which do not appear in a sufficient number of transactions,
or those that are present in nearly all transactions). This type of
support filtering can be useful in eliminating noise from the
data, such as that generated by shallow navigational patterns of
``non-active" users, and pageview references with minimal knowledge
value for the purpose of personalization.
Usage preprocessing ultimately results in a set of n pageview records
appearing in the transaction file,
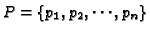 ,
,
with each pageview record uniquely represented by its
associated URL, and a set of m user transactions,
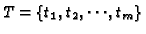 ,
,
where each
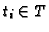 is a subset of P. To
facilitate various data mining operations such as clustering, we view
each transaction t as an n-dimensional vector over the space of
pageview references,
is a subset of P. To
facilitate various data mining operations such as clustering, we view
each transaction t as an n-dimensional vector over the space of
pageview references,
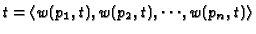 ,
,
where w(pi, t) is a weight, in the transaction t, associated with
the pageview represented by 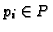 .
The weights can be determined
in a number of ways, for example, binary weights can be used to
represent existence or non-existence of a product-purchase or a
documents access in the transaction. On the other hand, the weights can
be a function of the duration of the associated pageview in order to
capture the user's interest in a content page. The weights may also, in
part, be based on domain-specific significance weights assigned by the
analyst.
Content preprocessing involves the extraction of relevant features from
text and meta-data. Meta-data extraction becomes particularly important
when dealing with product-oriented pageviews or those involving
non-textual content. In the current implementation of our framework
features are extracted from meta-data embedded into files in the form
of XML or HTML meta-tags, as well as from the textual content of pages.
In order to use features in similarity computations, appropriate
weights must be associated with them. For features extracted from
meta-data, we assume that feature weights are provided as part of the
domain knowledge specified by the site designer. For features extracted
from text we use a standard function of the term frequency and inverse
document frequency (tf.idf) for feature weights as commonly used in
information retrieval [5,15].
Specifically, each pageview p is represented as a k-dimensional
feature vector, where k is the total number of extracted features
from the site in a global dictionary. Each dimension in a feature
vector represents the corresponding feature weight within the pageview.
Thus, the feature vector for a pageview p is given by:
.
The weights can be determined
in a number of ways, for example, binary weights can be used to
represent existence or non-existence of a product-purchase or a
documents access in the transaction. On the other hand, the weights can
be a function of the duration of the associated pageview in order to
capture the user's interest in a content page. The weights may also, in
part, be based on domain-specific significance weights assigned by the
analyst.
Content preprocessing involves the extraction of relevant features from
text and meta-data. Meta-data extraction becomes particularly important
when dealing with product-oriented pageviews or those involving
non-textual content. In the current implementation of our framework
features are extracted from meta-data embedded into files in the form
of XML or HTML meta-tags, as well as from the textual content of pages.
In order to use features in similarity computations, appropriate
weights must be associated with them. For features extracted from
meta-data, we assume that feature weights are provided as part of the
domain knowledge specified by the site designer. For features extracted
from text we use a standard function of the term frequency and inverse
document frequency (tf.idf) for feature weights as commonly used in
information retrieval [5,15].
Specifically, each pageview p is represented as a k-dimensional
feature vector, where k is the total number of extracted features
from the site in a global dictionary. Each dimension in a feature
vector represents the corresponding feature weight within the pageview.
Thus, the feature vector for a pageview p is given by:
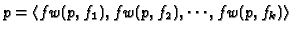
where fw(p,fj), is the weight of the jth feature in pageview 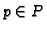 ,
for
,
for
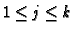 .
For features extracted from textual content
of pages, the feature weight is obtained as the normalized tf.idf value
for the term. Finally, in order to combine feature weights from
meta-data (specified externally) and feature weights from the text
content, proper normalization of those weights must be performed as
part of preprocessing. The feature vectors obtained in this way are
organized into an inverted file structure containing a dictionary of
all extracted features and posting files for each feature specifying
the pageviews in which the feature occurs along with its weight.
Conceptually, this structure can be viewed as a feature-pageview matrix
in which each column is a feature vector corresponding to a pageview.
.
For features extracted from textual content
of pages, the feature weight is obtained as the normalized tf.idf value
for the term. Finally, in order to combine feature weights from
meta-data (specified externally) and feature weights from the text
content, proper normalization of those weights must be performed as
part of preprocessing. The feature vectors obtained in this way are
organized into an inverted file structure containing a dictionary of
all extracted features and posting files for each feature specifying
the pageviews in which the feature occurs along with its weight.
Conceptually, this structure can be viewed as a feature-pageview matrix
in which each column is a feature vector corresponding to a pageview.
Next: Discovery of Aggregate Usage
Up: A Web Mining Framework
Previous: System Architecture
Bamshad Mobasher
2000-08-14