

Next:Data
Preparation for UsageUp:A
Web Mining FrameworkPrevious:A
Web Mining Framework
System Architecture
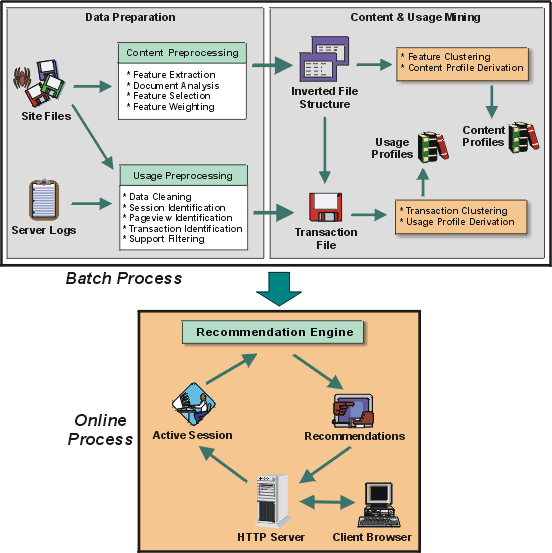
Figure 1 depicts a general architecture
for Web personalization based on usage and content mining. The overall
process is divided into two components: the offline component which is
comprised of the data preparation and specific Web mining tasks, and the
online component which is a real-time recommendation engine. The data preparation
tasks result in aggregate structures containing the preprocessed usage
and content data to be used in the mining stage. Usage mining tasks can
involve the discovery of association rules, sequential patterns, pageview
clusters, or transaction clusters, while content mining tasks may involve
feature clustering (based on occurrence patterns of features in pageviews),
pageview clustering based on content or meta-data attributes, or the discovery
of (content-based) association rules among features or pageviews. In this
paper, we focus on the derivation of usage profiles from transaction clusters,
and the derivation of content profiles from feature clusters. In the online
component of the system, the recommendation engine considers the active
server session in conjunction with the discovered patterns and profiles
to provide personalized content. The personalized content can take the
form of recommended links or products, targeted advertisements, or text
and graphics tailored to the user's perceived preferences as determined
by the matching usage and content profiles.
Figure 1: A general framework for automatic personalization
based on Web Mining
 |
Next:Data
Preparation for UsageUp:A
Web Mining FrameworkPrevious:A
Web Mining Framework
Bamshad Mobasher
2000-08-14