
Next: Discovery of Content Profiles
Up: A Web Mining Framework
Previous: Data Preparation for Usage
The transaction file obtained in the data preparation stage can be used
as the input to a variety of data mining algorithms. However, the
discovery of patterns from usage data by itself is not sufficient for
performing the personalization tasks. The critical step is the
effective derivation of good quality and useful (i.e., actionable)
``aggregate profiles" from these patterns. Ideally, a profile captures
an aggregate view of the behavior of subsets of users based their
common interests or information needs. In particular, aggregate
profiles must be able to capture possibly overlapping interests of
users, since many users may have common interests up to a point (in
their navigational history) beyond which their interests diverge.
Furthermore, they should provide the capability to distinguish among
pageviews in terms of their significance within the profile.
Based on these requirements, we have found that representing usage
profiles as weighted collections of pageview records provides a great
deal of flexibility. Each item in a usage profile is a URL representing
a relevant pageview, and can have an associated weight representing its
significance within the profile. The profiles can be viewed as ordered
collections (if the goal is to capture the navigational path profiles
followed by users [12]), or as unordered (if the focus is on
capturing associations among specified content or product pages). This
uniform representation allows for the recommendation engine to easily
integrate different kinds of profiles (i.e., content and usage
profiles, as well as multiple profiles based on different pageview
types). Another advantage of this representation is that the profiles,
themselves, can be viewed as pageview vectors, thus facilitating the
task of matching a current user session with similar profiles using
standard vector operations.
Given the mapping of user transactions into a multi-dimensional space
as vectors of pageview, standard clustering algorithms, such as
k-means, generally partition this space into groups of transactions
that are close to each other based on a measure of distance or
similarity. Such a clustering will result in a set
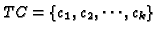
of clusters, where each ci is a subset of the set of
transactions T. Ideally, each cluster represents a group of users
with similar navigational patterns. However, transaction clusters by
themselves are not an effective means of capturing an aggregated view
of common user profiles. Each transaction cluster may potentially
contain thousands of user transactions involving hundreds of pageview
references. Our ultimate goal in clustering user transactions is to
reduce these clusters into weighted collections of pageviews which
represent aggregate profiles.
An effective method for the derivation of profiles from transaction
clusters was first proposed in [8]. For each transaction
cluster 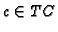 ,
we compute the mean vector mc. The mean value
for each pageview in the mean vector is computed by finding the ratio
of the sum of the pageview weights across transactions in c to the
total number of transactions in the cluster. The weight of each
pageview within a profile is a function of this quantity thus obtained.
In generating the usage profiles, the weights are normalized so that
the maximum weight in each usage profile is 1, and low-support
pageviews (i.e. those with mean value below a certain threshold
,
we compute the mean vector mc. The mean value
for each pageview in the mean vector is computed by finding the ratio
of the sum of the pageview weights across transactions in c to the
total number of transactions in the cluster. The weight of each
pageview within a profile is a function of this quantity thus obtained.
In generating the usage profiles, the weights are normalized so that
the maximum weight in each usage profile is 1, and low-support
pageviews (i.e. those with mean value below a certain threshold 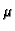 )
are filtered out. Thus, given a transaction cluster c, we construct a
usage profile prc as a set of pageview-weight pairs:
)
are filtered out. Thus, given a transaction cluster c, we construct a
usage profile prc as a set of pageview-weight pairs:
where the significance weight,
weight(p, prc), of the pageview p
within the usage profile prc is given by:
and w(p, t) is the weight of pageview p in transaction 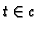 .
Each profile, in turn, can be represented as vectors in the original
n-dimensional space.
.
Each profile, in turn, can be represented as vectors in the original
n-dimensional space.
Next: Discovery of Content Profiles
Up: A Web Mining Framework
Previous: Data Preparation for Usage
Bamshad Mobasher
2000-08-14