Answer: Use R to define the dataset vector x and the vector of breakpoints for the histogram:
> x <- c(0.5, 0.5, 0.5, 1, 1.5, 1.5, 1.5) > x [1] 0.5 0.5 0.5 1.0 1.5 1.5 1.5 > b <- c(0, 1, 2) > b [1] 0 1 2Now create the histogram with bins 0 to 1 and 1 to 2 using the breakpoints vector c(0, 1, 2):
> hist(x, breaks=b)Here is the histogram:
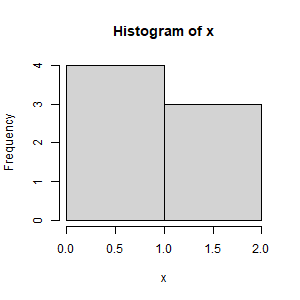
This histogram shows that the data point 1 is included in the left bin, because the histogram bins are right inclusive: (0, 1], (1, 2]. To make the histogram bins left inclusive (like SPSS, SAS, Minitab, and Python, set the right argument to FALSE:
hist(x, breaks=c(0, 1, 2), right=FALSE)Now this histogram is created:
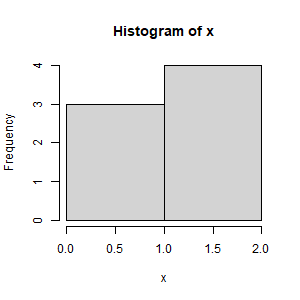
This shows that the bins are [0, 1), [1, 2), which are left inclusive.
Answer: Create one histogram with equal bin widths: [0, 1], (1, 2], and another histogram with unequal bin widths:
> x <- c(0.5, 0.5, 0.5, 1.5, 1.5) > b1 <- c(0, 1, 2) > b2 <- c(0, 1, 4) > hist(x, breaks=b1, main="Equal Width Bins") > hist(x, breaks=b2, main="Unequal Width Bins")The resulting histograms:
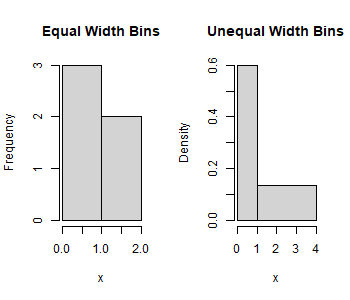
For the Equal Width Bins histogram, the vertical axis label is Frequency and the vertical units are the counts in each bin; for the Unequal Bin Widths histogram, the vertical label is Density and the vertical units are fraction of observations per horizontal unit.
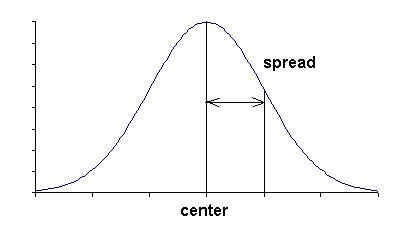
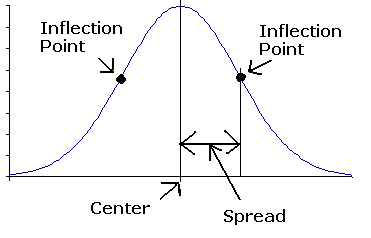
Ans: A critical point of a curve is where the slope of the curve is horizontal For a normal curve, the x-value of the critical point is the center of the curve. The normal curve is symmetric around the center.
Answer: an inflection point of a curve is where the curve changes from concave down to concave up, or vice versa.
Answer: the sample mean is another name for the sample average. If x1, x2, ... , xn is the dataset, the sample mean is the sum of the observations divided by the number of the observations:
X = (x1, x2, ... , xn) / n
{kind=link}