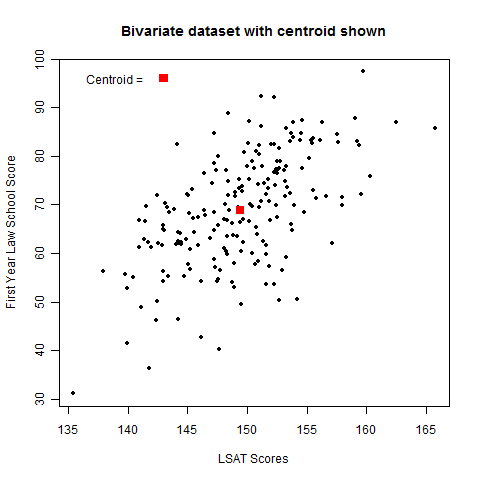
A bivariate dataset is a dataset with two variables x and y. Some examples are height and weight,
automobile weight and gas mileage, floor area of a home and its price.
The samples means x, y form the centroid
or center of gravity of the dataset.
The sample means x, y
and standard deviations sx, sy
are useful summary statistics for x and y.
In addition to these four statistics, we need a fifth statistic, the sample covariance, that
describes the degree to which x and y vary linearly together.
The sample covariance is defined as
sxy =
(x1 -
x)(y1 - y) + ... +
(xn -
x)(yn -
y)
n - 1
The sample correlation between two variables is a normalized version of the covariance:
r = sxy / sx sy
It indicates the amount of linear association between x and y.
The correlation r is always between -1 and 1 inclusive.
For math majors: use the
Cauchy-Schwartz Inequality from
linear algebra to prove that -1 ≤ r ≤ 1. Another way to see this is that r is the
cosine of the angle between two data vectors, which is always between -1 and 1.
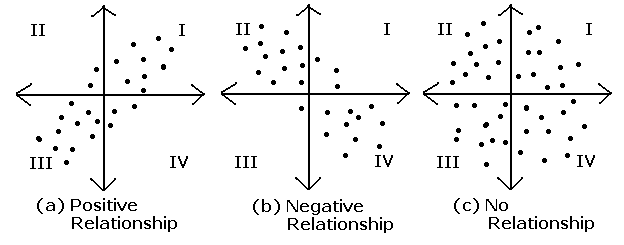
Here are three scenerios showing what can happen with the z-scores of x and y:
x and y have a positive relationship: if the value of x increases, the value of y tends to increase as well.
Most of the z-score points are in Quadrants I and III, so the average of the products and the
correlation are positive.
x and y have a negative relationship: if the value of x increases, the value of y tends to decrease.
Most of the z-score points are in Quadrants II and IV, so the average of the products and the correlation are
negative.
x and y have no relationship: if x increases, y has no tendency to either increase or decrease. The z-score points are
equally distributed in Quadrants I, II, III, and IV. The positive and negative products
average out, so the correlation is close to zero.
The coefficient of determination or R2 is the square of the correlation.
The R2 value is the proportion of variation in the dependent variable that can be explained by the variation in the
independent variable.
R2 is easier to interpret than the correlation r. Values of R2 close to 1 are good, values close
to 0 are poor.
How large R2 must be to be considered good depends on
the discipline. R2 is usually expected to be larger in the physical sciences
than it is in biology or the social sciences. In finance or marketing, it also
depends on what is being modeled. Here are professor Jost's rule-of-thumb
cutoffs for r and R2 to be considered good in various disciplines:
Discipline
r Cutoff
R2 Cutoff
Physics
r ≥ 0.95 r ≤ -0.95
r ≥ 0.9
Chemistry
r ≥ 0.9 r ≤ -0.9
r ≥ 0.8
Biology
r ≥ 0.7 r ≤ -0.7
r ≥ 0.5
Social Science
r ≥ 0.5 r ≤ -0.5
r ≥ 0.25
Caution: the sample correlation and R2 are misleading if
there is a nonlinear relationship between the independent and dependent variables.
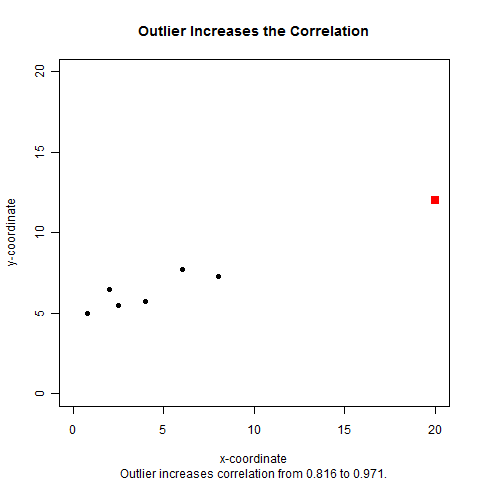
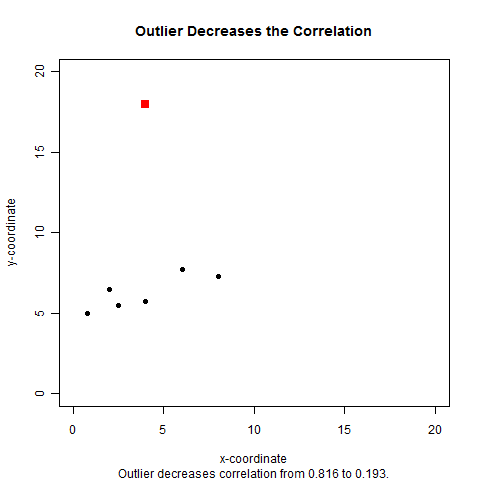
Correlations can also be thrown off by outliers. A single outlier can either
increase or decrease the correlation.
In each case, the correlation is 0.816 without the outlier.
{kind=link}
{kind=link}
{kind=link}
{kind=link}