In all experiments we measured both precision and coverage of recommendations against varying recommendation thresholds from 0.1 to 1.0. To consider the impact of window size (the portion of user histories used to produce recommendations) we performed all experiments using window sizes of 1 through 4. Furthermore, we considered the impact of a global support threshold by varying the minimum support across all experiments. We compared these results with those produced by utilizing multiple support thresholds and all-kth-order recommendation model. Finally, we performed experiments to show the relative performance of our framework against the kNN technique for collaborative filtering. For the kNN method we chose k = 20 which seemed to provide the best overall results for the current data set, and we used the standard vector-space cosine similarity measure to generate nearest neighbors (from the training set) for the current active user session in the evaluation set.
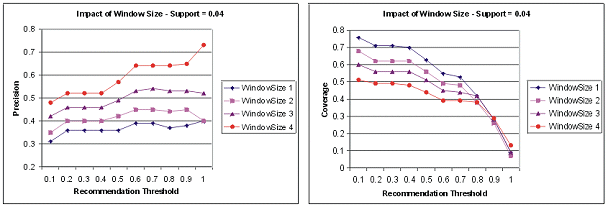
Figure 2 shows the impact of window size on precision and coverage of recommendations. The results show clearly that precision increases as a larger portion of user's history is used to generate recommendations. Coverage, on the other hand is inversely affected by window size, although at higher recommendation thresholds the difference between various window sizes becomes smaller.
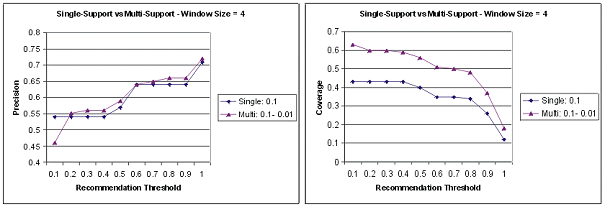
As expected, the experiments on the impact of support showed that a higher minimum support threshold during the mining stage results in lower coverage (but only slightly better precision). These results are not shown here. In general, it is desirable to use higher support thresholds in order to keep the model size small and to ensure the scalability of the association rule mining algorithm. However, as noted earlier, the higher support will result in missing some potentially important, yet infrequent, items as part of the recommendation set. In the context of Web personalization with clickstream data, the missed pageviews tend to be those that are particularly important (e.g., deeper content-oriented or product pages). Using the multiple support version of Apriori [8] helps alleviate this problem. Figure 3 shows the impact of using multiple support levels. In this experiment we selected several of the content-oriented pages situated more deeply in the site and assigned a minimum support of 0.01 to these pages. The other (navigational) pages were assigned a high support value of 0.1. The results are compared to using a single global minimum support threshold of 0.1. As the results suggest, the use of multiple support thresholds maintains the overall precision of recommendations while dramatically increasing the overall coverage (even at high recommendation thresholds).
 |
The use of all-kth-order models (i.e., using varying-sized windows over the active session) has a similar impact as the use of multiple support levels. Figure 4 shows that all-kth-order model achieves similar precision (or better for higher recommendation thresholds) while improving the coverage of recommendations. The figure depicts the results for window size 3 and support threshold of 0.04, however, the relative results were similar for other combinations of window sizes and support values.
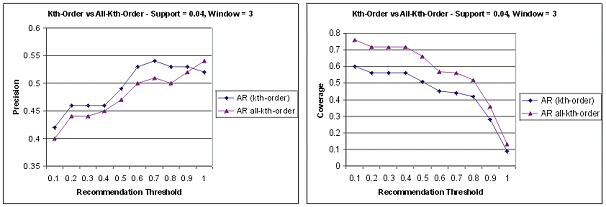 |
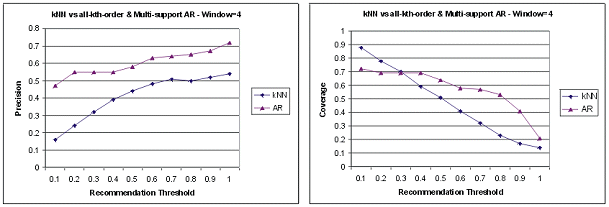
Figure 5 depicts the comparison of recommendation effectiveness between the kNN method for collaborative filtering and the combined association rule framework (including multiple support levels and all-kth-order recommendation model). The results for window size 4 show dramatic improvement in precision and an overall improvement in terms of coverage. The comparison with other window sizes (not shown) indicated that with increasing window size, the advantages of the association rule based method for both metrics become more pronounced.
Bamshad Mobasher (mobasher@cs.depaul.edu)