The recommendation engine takes a collection of frequent itemsets as input and generates a recommendation set for a user by matching the current user's activity against the discovered patterns. The recommendation engine is on-line process, therefore its efficiency and scalability are of paramount importance. In this section, we represent a data structure for storing frequent itemset and a recommendation generation algorithm which uses this data structure to directly produce real-time recommendations from itemsets without the need to first generate association rules.
We use a fixed-size sliding window over the current active session to capture the current user's history depth. For example, if the current session (with a window size of 3) is <A, B, C>, and the user references the pageview D, then the new active session becomes <B, C, D>. This makes sense in the context of personalization since most users go back and forth while navigating a site to find the desired information, and it may not be appropriate to use earlier portions of the user's history to generate recommendations. Thus, the sliding window of size n over the active session allows only the last n visited pages to influence the recommendation value of items in the recommendation set.
The recommendation engine matches the current user session window with itemsets to find candidate pageviews for giving recommendations. Given an active session window w, we only consider all itemsets of size |w|+1 satisfying a specified support threshold and containing the current session window. The recommendation value of each candidate pageview is based on the confidence of the corresponding association rule whose consequent is the singleton containing the pageview to be recommended. If the rule satisfies a specified confidence threshold requirement, then the candidate pageview is added to the recommendation set.
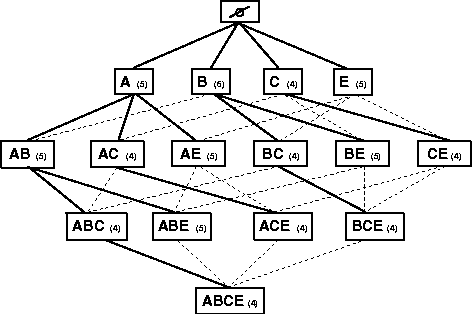
In order to facilitate the search for itemsets (of size |w|+1) containing the current session window w, during the mining process the discovered itemsets are stored in a directed acyclic graph, here called a Frequent Itemset Graph. The Frequent Itemset Graph is an extension of the lexicographic tree used in the tree projection algorithm of [1]. The graph is organized into levels from 0 to k, where k is the maximum size among all frequent itemsets. Each node at depth d in the graph corresponds to an itemset, I, of size d and is linked to itemsets of size d+1 that contain I at level d+1. The single root node at level 0 corresponds to the empty itemset. To be able to match different orderings of an active session with frequent itemsets, all itemsets are sorted in lexicographic order before being inserted into the graph. The user's active session is also sorted in the same manner before matching with patterns.
Given an active user session window w, sorted in lexicographic
order, a depth-first search of the Frequent Itemset Graph is performed
to level |w|. If a match is found, then the children of the
matching node n containing w are used to generate
candidate recommendations. Each child node of n corresponds to a
frequent itemset
![]() .
In each case, the pageview p is added to the recommendation set
if the support ratio
.
In each case, the pageview p is added to the recommendation set
if the support ratio
![]() is greater than or equal to
is greater than or equal to ![]() ,
where
,
where ![]() is a minimum confidence threshold. Note that
is a minimum confidence threshold. Note that
![]() is the confidence of the association rule
is the confidence of the association rule
![]() .
The confidence of this rule is also used as the recommendation score
for pageview p. It is easy to observe that in this algorithm the
search process requires only O(|w|) time given active
session window w.
.
The confidence of this rule is also used as the recommendation score
for pageview p. It is easy to observe that in this algorithm the
search process requires only O(|w|) time given active
session window w.
To illustrate the process, consider the example transaction set given in Table 1.
Using these transactions, the Apriori algorithm with a frequency threshold of 4 (minimum support of 0.8) generates the itemsets given in Table 2.
Figure 1 shows the Frequent Itemsets Graph constructed based on the frequent itemsets in Table 2.
Now, given user
active session window <B, E>, the recommendation
generation algorithm finds items A and C as candidate
recommendations. The recommendation scores of item A and
C are 1 and 4/5, corresponding to the confidences of the rules
![]() and
and
![]() ,
respectively.
,
respectively.
It should be noted that, depending on the specified support threshold, it might be difficult to find large enough itemsets that could be used for providing recommendations, leading to reduced coverage. This is particularly true for sites with very small average session sizes. An alternative to reducing the support threshold in such cases would be to reduce the session window size. This latter choice may itself lead to some undesired effects since we may not be taking enough of the user's activity history into account. Generally, in the context of recommendation systems, using a larger window size over the active session can achieve the better prediction accuracy. But, as in the case of higher support threshold, larger window sizes also lead to lower recommendation coverage. In order to overcome this problem, we use all-kth-order method proposed in [14] in the context of Markov chain models. In Markov models, the order of the model corresponds to the number of prior events used in predicting a future event. The use of all-kth-order Markov models generally requires the generation of separate models for each of the k orders, often leading to high space complexity.
Our algorithm is extended to generate all-kth-order recommendations as follows. First, the recommendation engine uses the largest possible active session window as an input for recommendation engine. If the engine cannot generate any recommendations, the size of active session window is iteratively decreased until a recommendation is generated or the window size becomes 0. We also note that, in contrast to standard all-kth-order Markov models, our framework does not require additional storage since all the necessary information (for all values of k) is captured by the Frequent Itemset Graph described above.
Bamshad Mobasher (mobasher@cs.depaul.edu)