Assignment 2
Due: Friday, May 1
In this Assignment you will explore unsupervised knowledge discovery techniques
of association rule mining and sequential patterns mining. In particular you
will apply some of the techniques discussed in the lectures by tracing the
algorithms using sample data sets. You will also experiment with performing
market basket analysis using WEKA on a couple of real-world data sets that have
been preprocessed and prepared for the tasks in this assignment.
- Note: You must do this problem manually by hand-tracing the Apriori algorithm
discussed in the lectures [see lecture notes on
Association
Rule Discovery] rather than using a third party tool or program.
Consider the following transaction database. Each row represents a single
transactions in which the specified items have been purchased.
| Transaction ID |
Items Purchased |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 |
A,B,C,D
B,C,D,E,G
A,C,G,H,K
B,C,D,E,K
D,E,F,H,L
A,B,C,D,E,L
A,D,E,F,L
B,I,K,L
C,D,F,L
A,B,D,E,K
C,D,H,I,K
B,C,E,K
B,C,D,F
A,B,C,D
C,H,I,J
A,E,F,H,L
H,K,L
A,B,D,H,K
D,E,K
B,C,D,E,H |
- Applying the Apriori algorithm with minimum support of 30% find all the
frequent itemsets in the data set. For each step in the algorithm, give the
list of frequent itemsets that satisfy minimum support (i.e., for each
iteration i, give the set Li along with
the support values for the frequent itemsets).
- From the maximal frequent itemsets in part a, generate all association
rules that meet a minimum confidence of 75%. In addition to the
confidence also specify the Lift (improvement) values for each of the
final set of
rule you discovered.
- Suppose that we have the following site map associated with
a hypothetical
ecommerce Web site:
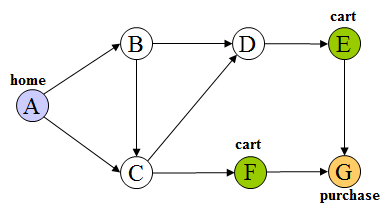
where A represents the event of visiting the homepage, E and
F represent the
action of adding items (perhaps from two different product categories) to the shopping cart, and
G represents the purchase of the item(s) in the
cart.
We also have some preprocessed and sessionized usage data recorded in the server log
capturing past user navigation in the Web site. These sessions are stored in a sessions data file. Each row in the data file represents pages accessed by a
user during one session in the order in which these pages were accessed.
Construct a Markov chain [see lecture notes on
Mining Sequential & Navigational
Patterns] based on the above site graph with states
corresponding to the pages in the graph and transition probabilities computed
using the training session data. You should also add a starting state with
transitions to all pages that appear as starting pages in the session data, as
well as a final state with transitions from pages that represent the end of a
session. Show the computed transition
probabilities as labels on the edges of the complete state transition diagram
for the Markov Chain.
After computing the transition probabilities, answer each of the following
using only the Markov model (not the original session data). Be sure to show the
details of your computations.
- What is the probability that someone will visit page D?
-
What is the probability that someone visiting the homepage will go on to visit
additional pages in the site?
- What is the probability that a user who starts from the homepage will place
something in his/her shopping cart?
- What is the probability that a user who starts from the homepage will
actually make a purchase?
- What is the probability of cart abandonment (i.e., the probability
that someone who has something in the shopping cart will exit the site
without making a purchase)?
For this problem you will use some preprocessed and
aggregated clickstream data from a real e-commerce site, and use association
rule mining to perform market basket analysis on the visitor session data.
[Note: Please watch the class video
Association Rule
Mining with WEKA (23 min) demonstrating the use of Apriori algorithm
in WEKA for market basket analysis.]
There are two primary types of products sold through the above site,
leg care products, and leg ware products. Each category includes various
subcategories and individual products from multiple vendors. There is also
a separate categorization of products by specialized "Collections" and
by "Assortments." The data collection mechanism, in addition to capturing clickstream page-level data, also
captures the information on categories, subcategories, assortments, and
collections of products accessed in a given session.
For simplicity, the provided data combines and aggregates visited pages from
the log files, category and subcategory names, and product related content
pages/categories. The aggregate data contains a total of 182 attributes
corresponding to pages or categories. These attributes are listed in the file
Leg-Pages.txt. The session data is provides in ARFF
format in the file legs.arff (in a Zip archive). This data contains a total
of 7296 sessions (each row in the data). For the purpose of market basket
analysis in WEKA, the session data is represented in relational format with
unary categorical attributes (a value of "Y" indicates that the corresponding
page/category was visited in the session, while a value of "?" indicates that
the page/category is missing from the session). Thus, a typical association rule
might look similar to the following: /Products/Legwear=Y
/Products/Legwear/Berkshire=Y ==> Collection: Better Than Bare - Queen=Y
or Category: Health Supplements=Y ==> Subcategory:
Bones & Joints=Y Your task in this problem is as follows:
- Load the data into WEKA and review the distributions in the data (go
down the list of attributes and make a note of which pages or products
are most frequent and which are least frequent - you can list the top 3
and the bottom 3 in your submission.
- Perform association rule mining using Apriori algorithm with a "lowerBoundMinSupport"
of 0.05 and using Lift of 2.5 as the minMetric for filtering the rules.
Also, set "outputItemsets" to "True" so that you can also view the
frequent items sets of different sizes in addition to the rules. Write a
short summary of your observations, including any significant or
interesting (e.g., unobvious or unexpected) associations you observe in
the data based on the results. Save your result set and submit along
with your assignment submission
- Next, run the Apriori algorithm with a lower "lowerBoundMinSupport"
so that you can identify associations at a more granular level (e.g.,
the level of individual products brands rather than higher level
categories). You might want to start with 0.025 and go lower if
necessary. Experiment with this threshold, as well as the Lift or
Confidence metrics in different runs and pick the result set that seems
to provide the most useful information (e.g., not too many obvious or
noisy rules and not too few general rules). Again, provide a short
summary of your observations, including some examples of rules or
associations that you find interesting or useful.
-
The marketing department of a financial firm keeps records on customers, including
demographic information and the type of accounts. When launching a new product,
such as a "Personal Equity Plan" (PEP), a direct mail piece, advertising the
product, is sent to existing customers, and a record kept as to whether that customer
responded and bought the product. Based on this store of prior experience, the managers
decide to use data mining techniques to build customer profile models. In this
particular problem we are interested only in deriving (quantitative) association rules
from the data (in a future assignment we will consider the use of classification
with this data).
The data contains the following fields
| id |
a unique identification number |
| age |
age of customer in years (numeric) |
| sex |
MALE / FEMALE |
| region |
inner_city/rural/suburban/town |
| income |
income of customer (numeric) |
| married |
is the customer married (YES/NO) |
| children |
number of children (numeric) |
| car |
does the customer own a car (YES/NO) |
| save_acct |
does the customer have a saving account (YES/NO) |
| current_acct |
does the customer have a current account (YES/NO) |
| mortgage |
does the customer have a mortgage (YES/NO) |
| pep |
did the customer buy a PEP (Personal Equity Plan) after the last mailing (YES/NO) |
The data is contained in the file bank-data.csv.
Each record is a customer description where the "pep" field indicates whether or not
that customer bought a PEP after the last mailing.
Your goal is to perform Association
Rule discovery on the data set using the Weka package.
Note: Association rule mining requires discretization of continuous
variables. This task can be performed in the data transformation step or (in
some cases) by the mining program. WEKA is a full data mining suite which includes
various preprocessing modules (filters). When using WEKA, you will first apply the relevant
preprocessing filters to transform the data before you performing association rule discovery.
First perform the necessary preprocessing steps required for association rule
mining. Specifically, the "id" field will need to be removed and the numerical
attributes must be discretized.
Next perform association rule discovery on the transformed data. Experiment with
different parameters so that you get at least 20-30 strong rules (e.g., rules
with high lift and confidence which at the same time have relatively good support).In
WEKA Apriori algorithm interface set "outputItemsets" to "True" so that you
can also view the frequent items sets of different sizes in addition to the
rules. Select
the top 5 most "interesting" rules and for each specify the following:
- an explanation of the pattern and why you believe it is interesting based on
the business objectives of the company;
- any recommendations based on the discovered rule that might help the company
to better understand behavior of its customers or in its marketing campaign.
Note: The top 5 most interesting rules are most likely not the top 5 in the result
set of the Apriori algorithm. They are rules that, in addition to having high support, lift,
and confidence, also provide some non-trivial, actionable knowledge based on the underlying
business objectives.
|
