We know that a bell-shaped histogram is said to have a normal
distribution.
However, in practice, it is often difficult to look at a histogram
and determine how close its distribution is to normal.
An easier way to tell if a dataset is normally distributed is
to look at the normal plot. If the normal plot is close to a straight
line, the distribution of the dataset is close to normal.
Normal Scores
To define normal scores using Van der Waerden's method,
find z-scores that divide the standard normal curve into n+1 equal
areas of 1/(n+1) each. For example, the normal scores when n = 5 are
defined by the bins (-∞, -0.97],
(-0.97, -0.43], (-0.43, 0.00], (0.00, 0.43], [0.43, 0.97],
(0.97, ∞). Each of these bins has area 1/(5+1) = 0.1667.
This means that the normal scores for a dataset with n = 5 are
-0.97, -0.43, 0.00, 0.43, and 0.97.
We can also see that the bins
(-∞, -0.97], (-∞, -0.43], (-∞, 0.00], (-∞, 0.43],
(-∞, 0.97] have areas 1/6 = 0.1667, 1/3 = 0.3333, 1/2 = 0.5000,
2/3 = 0.6667, 5/6 = 0.8333, respectively.
Q-Q Plots
A normal plot or Q-Q plot is formed by plotting
the normal scores defined in the previous section are plotted on the y-axis
vs. the actual sorted data values on the x-axis.
If the normal plot is close to a straight line, we conclude that
the dataset is close to normal.
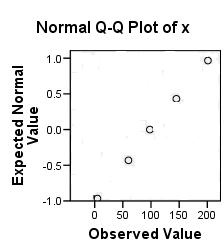
Here is a normal plot of the dataset
3 60 98 145 201
The dataset values on the y-axis are plotted against the normal scores
-0.97 -0.43 0.00 0.43 0.97.
Here is the resulting normal plot:
The normal plot is approximately a straight line, so we conclude that
the original dataset is close to normally distributed.
Q-Q Plots with SPSS
Example: Obtain the normal plot of the
NBS-10 data.
Select Analyze >> Descriptive Statistics >> Q-Q Plots.
Move Difference to the Variables box, and select Van der Vaerden as the Proportion
Estimation Formula.
Nonnormality
What if the dataset is not normal?
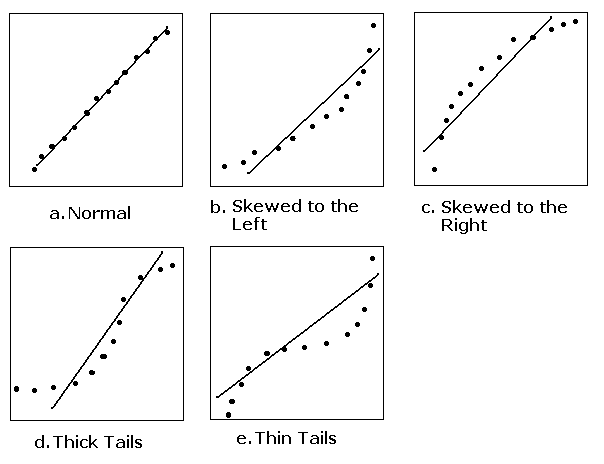
Here are the normal plots of datasets compare a normal dataset with
other datasets tha deviate from normality in various ways.
In these normal plots, the actual data points are plotted on the
x-axis and the expected normal scores (Van der Waerden's method) are
plotted on the y-axis.
Data are normal. All the points of the normal plot fall
roughly on the reference line.
Data are skewed to the left. The data are further away on the
left and closer on the right than they would be if they were normal.
Data are skewed to the right. The data are closer on the left
and further away on the right than they would be if they were normal.
The distribution of the data has thick tails. The data are further
away on both the left and the right than they would be if they were
normal.
The distribution of the data has thin tails. The data are closer
on both the left and the right than they would be if they were
normal.