An Empirical Examination of Current High-Availability Clustering Solutions’ Performance
Abstract: Given the prevalence of High-Availability
Clusters today, we look at how much actual extra availability they provide
compared to a single server in the face of a set of common failures. We compare
three HA clustering solutions, AIX, Windows 2000 Advanced Server and Red Hat
Linux. We measure “uptime” of
the HA cluster and compare it with a similar non-HA configuration. While
looking strictly at performance as a measurable value determined by the success
of http clients’ attempted connections, other aspects of HA clustering that are
of concern to system administrator and network architects are examined as well.
I Introduction
High Availability and node clustering may be manna to marketing groups as companies and customers begin to expect websites and services that are constantly available; but for system administrators and for IT staff, does purchasing a high availability clustering solution always lead to more uptime?
Many vendors of major operating systems have recently begun to include high availability clustering features as part of their base operating system product or as add-on packages. While arguably HP (DEC) was the first company to successfully market the concept,4 IBM, Microsoft, Red Hat, and others have recently jumped onto the high availability clustering bandwagon.
There are some related technologies and terms that must be understood even though they are not part of this study. High availability clustering (HA clustering) may contribute to or work in tandem with these technologies, but they are separate aspects of creating a site or a service and are not required for HA. Load balancing is running an identical process simultaneously on multiple machines and dispatching queries or sessions between machines using a scheduling mechanism. Disaster recovery is planning for the loss of a physical machine and its associated physical site while being able to recover the service quickly or immediately. Fault tolerance usually refers to a system that can remain running correctly regardless of its encountering a certain number of hardware of software errors. A Distributed operating system is “a collection of independent computers that appear[s] to the users of the system as a single computer,” and consists of a “set of multiple interconnected CPUs working together.”6 The concept of distributed operating systems includes many wide-ranging configurations from parallel computing to large, loosely-coupled systems, but generally the more loosely-coupled the member systems are, the less likely that the overall system is considered a distributed operating system. The object of this study, HA clustering, generally refers to two or more peer machines with at least one watcher or watchdog process running on each machine to ensure that any designated highly-available services remain running on at least or exactly one machine in the cluster. The watchdog processes communicate with their peer processes on the other machines in the cluster via a heartbeat sent across various networks. HA clustering as it is studied here does not fall under the definition of a distributed operating system as it is loosely coupled; it does not maintain transactional integrity in the event of a fault; and it does not provide a global IPC mechanism as would be expected in a distributed operating system.
HA clustering may provide some features such as load balancing, geographic distribution (which in-turn would contribute to disaster recovery), scalability, and the ability to perform “rolling” upgrades; it also removes the single point of failure (SPOF) that many architects try to avoid when designing a production enterprise. Youn10 et al list the requisite features of a HA clustering system.
- SPOF [avoided by] using redundancy
- Single image to the outside world using a single virtual IP address and hostname
- Automated fault management and recovery
- Multiple access paths from each cluster node to each resource group (set of HA services)
- Simple abstraction for applications and administrators
- Undisrupted (or minimal disrupted) services during failover.
The key functional aspect of HA Clustering is that it is supposed to provide fault tolerance from the perspective of the highly-available service. “If a computer breaks down, the functions performed by that computer will be handled by some other computer in the cluster.”2
During enterprise design, the choice of an HA cluster instead of a
single server can lead to significantly higher costs. HA clustering requires at
least twice as much hardware, twice as many software licenses, more network
connectivity, more rack space, more power, and more maintenance time. The HA
processes themselves use memory, CPU time and bandwidth. Often the HA software
components’ licenses also cost much more than the base operating system alone.5
II Research Goal.
Given that the defining aspect of HA clustering is that it provides fault tolerance for the defined highly-available service, this study attempts to determine the extent that HA provides fault tolerance for a simple HTTP service in the face of an arbitrary set of failures within the enterprise’s environment. Since this study is performed across three operating systems with different HA component designs but with a similar network architecture/topology, it also may indicate something about the relative merits of the differing vendors’ HA implementations for this specific service. This study’s results may help network architects, system administrators, and other IT technicians to make better decisions about whether HA clustering is appropriate for their service. The conclusion that may be inferred from the results may determine whether the complexity and interdependencies that HA clustering introduces into an environment enhance, degrade, or make little difference to the uptime of the environment.
It should be noted that the set of failures or faults that is tested against was arbitrarily generated and it is not based on any data or distribution of expected failures. When designing the set, an attempt was made to mimic the types of failures that are experienced in a production environment. Also, this failure set was designed to test the various levels of recursive restartability12 from a simple service failure, to IP failure, to a full node failure, to a full physical site power failure. More discussion of the failures and the generality of the failures follows in the methodology section. Comparing uptime values of the same service in HA versus that uptime for that service in non-HA environments over a set of failures or even over a single failure provides valuable information regarding the worthiness of HA clustering as an element of design.
III Methodology
Generally, two machines (LAB1 and LAB2) are placed in a cluster
configuration with at least two networks of communication between them. One
network is designated as the public network; it is on this network that the HA
service is present. Other networks or communication links are designated as
private. Apache HTTP Server 2.0 is installed on both machines, and a small
website consisting of static text and images is configured to be served to the
public network.9 All servers use the same version of Apache. The
clustering product is then configured to communicate between the two machines
and to monitor the Apache httpd process. With each HA process there are often
other aspects of the operating system that must be present. These may include
filesystems, message queues, IP addresses, hostnames, and configuration files. The
network design of this experiment represents a common configuration.2
While great care is taken to use the latest BIOS and machine microcode, the
latest available patches for the operating systems, the latest web server
program, and the recommended configurations, as this study is empirical and
designed to reflect real-world failures, node lockups, failures, “bluescreens” and other anomalies are not omitted from the
reported data.
The failover type between the two machines is set to be cascading. A cascading failover configuration designates a preferred host machine for the HA process. When the process fails to run on the preferred host, then the process is started on a host with a lower preference and the dependant aspects of the operating system are migrated to this secondary host. In this study, there is only one requisite aspect that must be present for the process to run; there is a single Virtual IP address (VIP) for the website of 9.16.6.46. The filesystem containing the website files is manually replicated between the servers and is static. In a cascading system, if the preferred host becomes available at a later time then it attempts to reacquire the HA process from the less-preferred system. This is known as failback. Contrasting a cascading system is a rotating system where there are no preferred systems and the HA processes will fail to hosts based on a round-robin priority with no failback.
AIX
For the AIX HACMP testing we use a network design consisting of two web servers connected with two networks as well as a serial cable running between the two machines. HACMP sends heartbeat information across all three communication paths. The two servers are loaded with AIX 5.2 and the HACMP/ES add-on package for AIX to be used as clustering software. The “public” network is the token ring network, and the “private” or heartbeat network is 100 Mbps Ethernet, the serial link is considered an additional private network.
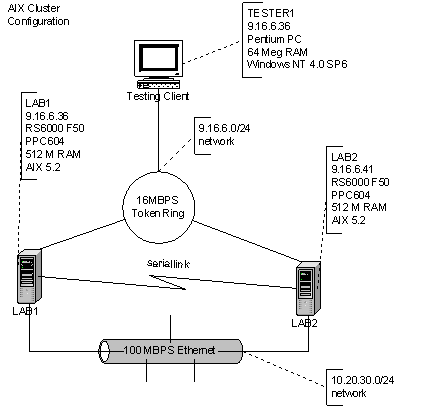
While the configuration is generally a default configuration of HA-Clustering for AIX, some specific exceptions follow. On the active server, the httpd process is monitored at 15 second intervals for its presence, and restarted once if it is not present. After a start of httpd, there is a 30 second wait before monitoring of the process by the watchdog resumes. The httpd process must be stable for 129 (30 + 99) seconds after a restart to reset the failure count to 0. The heartbeat across the serial link occurs every 2 seconds and 10 consecutive missed heartbeats constitute a failure. The heartbeats across both the public and private packet networks occur at 1-second intervals and 10 consecutive missed heartbeats constitute a failure.
Windows 2000 Advanced Server
For the Windows 2000 Advanced Server cluster, we use a network design consisting of two web servers connected with two networks. MSCS sends heartbeat information across both communication paths. The two servers are loaded with Windows 2000 Advanced Server and the GeoCluster software package from NSI software to simulate a shared storage array. One of the limitations of Windows clustering is that it “requires” a shared disk array; GeoCluster removes this limitation by mirroring the shared storage across the cluster members via IP connectivity. The “public” network is the token ring network, and the “private” network is 100 Mbps Ethernet. Unlike AIX and Linux, there is no serial link.
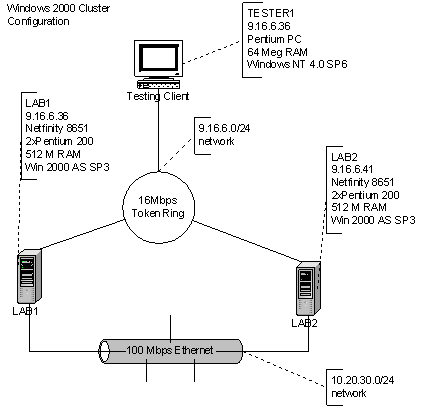
Again, like the AIX trials, the configuration is generally a default configuration of MSCS for Windows Advanced Server with GeoCluster, but some specific exceptions follow. A feature of Windows clustering is that it will limit failovers over time, preventing “ping-ponging;” for testing purposes, infinite failovers are allowed. On the active server, the httpd process is monitored at 15 second intervals for its presence, and restarted once if it is not present. After a start of httpd, there is a 30 second wait before monitoring of the process by the watchdog resumes. The httpd process must be stable for 129 seconds after a restart to reset the failure count to 0. Network card media-sensing is disabled due to GeoCluster recommendations. The heartbeats occur across both the public and private packet networks at 1-second intervals and 10 consecutive missed heartbeats constitute a failure. These settings are intended to make this configuration similar to the other two clustering systems tested.
Red Hat Linux AS with “Heartbeat”7 and
“Monit”8
For the Red Hat Linux cluster, we use a network design consisting of two web servers connected with two networks as well as a serial cable running between the two machines. The two servers are loaded with Red Hat Advanced Server. It should be noted that RHAS provides its own clustering solution, but we were unable to successfully configure it to use token ring, so we turn to two programs that do work, Heartbeat and Monit. Heartbeat sends heartbeat information across all three communication paths, and Monit watches the heartbeat process and the httpd process. The “public” network is the token ring network, and the “private” networks are the 100 Mbps Ethernet and the serial connection.
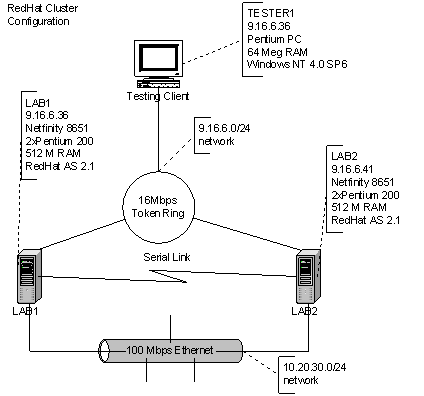
As with the other trials, the configuration
is generally a default configuration of Monit and of Heartbeat, but some
specific exceptions follow. On the active server, the httpd process is
monitored at 15 second intervals for its presence, and restarted once if it is
not present. After a start of httpd, there is a 30 second wait before
monitoring of the process by the watchdog resumes. The httpd process must be
stable for 130 seconds after a restart to reset the failure count to 0. The
heartbeats across both the public and private packet networks occur at 1-second
intervals and 10 consecutive missed heartbeats constitute a failure. The
heartbeats across the serial network also occur at 2 second intervals and 10
misses are a failure. These settings are intended to make this configuration
similar to the other two clustering systems tested.
The Testing Machine
The testing machine is a Windows NT 4.0 machine on the public network. There is no specific non-default configuration on the machine except that it is set to refresh its ARP cache every five seconds. This is to minimize effects of IP address failover; in a well-configured HA environment, a router would be set similarly. The testing program is Microsoft Web Application Stress Tool 1.1 (WAS.) WAS is designed to simulate multiple users from multiple machines while only using a single machine; it has features such as virtual users and random page-choice.11 It is configured to run with 5 virtual users and to run a test with an equal distribution of every page on the served website, but choosing randomly by using its page-grouping. Each test length is 10 minutes.
Failures
In an actual production environment, often the environment is not static and changes are being made on and around the clustered servers. Many types of faults can occur, not the least of which can include things such as on-site technicians accidentally unplugging the wrong cable or administrative technicians misconfiguring ports and cards. For this experiment we take about 14 events and apply them to the systems while the testing machine is generating a load against the cluster or single server. Each event occurs at 60 seconds into the trial, and the trial lasts for 10 minutes total.
1)
Baseline.
No events
2)
Kill process
on primary server.
This simulates a simple fault that caused an abend
to the process but did not take out the machine.
For this experiment, a kill -9 (or in Windows, the similar point-and-click
command) is issued to all web-server related processes on the primary server.
3)
Kill process
on primary server, and hold the process down for 30 seconds.
This simulates a core dump that takes a long time or a more complex fault.
For this experiment, a kill -9 (or in Windows, the similar point-and-click
command) is issued to all web-server related processes on the primary server,
and immediately the httpd binary is renamed. After 30 seconds, on the primary
server, the httpd binary is restored.
4)
Kill process
on primary server, hold down for 30 seconds and fail to start on second node.
This simulates a core dump or more complex fault, as well as a misconfiguration on the secondary server.
For this experiment, the httpd binary is renamed on the secondary server, and a
kill -9 (or in Windows, the similar point-and-click command) is issued to all
web-server related processes, and immediately the httpd binary is renamed.
After 30 seconds, on the primary server, the httpd binary is restored.
5)
Kill the
cluster/watchdog process on the primary server.
This simulates a bug in the cluster programming that causes an abend or a mistaken shutdown of the cluster processes.
For this experiment, a kill -9 (or in Windows, the similar
point-and-click command) is issued to all cluster related processes.
6)
Short power
failure on primary node.
This simulates a simple node power failure, technician error, or a
loose power-cable, etc.
An example of a technical error would be shutdown –Fr
or reboot.
For this experiment, the power cable is removed and then immediately replaced
on the primary node.
7)
Simultaneous
power failure on both nodes, primary recovers first.
This simulates a datacenter power failure. Which machine recovers
first is arbitrary.
For this experiment, the power cable is pulled from both servers simultaneously
and then replaced immediately on the primary server, 45 seconds later it is
replaced on the secondary server.
8)
Simultaneous
power failure on both nodes, secondary recovers first.
This simulates the other possible event from a datacenter power
failure.
For this experiment, the power cable is pulled from both servers simultaneously
and then replaced immediately on the secondary server. 45 seconds later it is
replaced on the primary server.
9)
For AIX and Linux, Loss of serial communication for 60 seconds.
This simulates a loose serial cable or technician error such as a
cable disconnect, a port misconfiguration, or a mistaken
command such as echo hello> /dev/tty0.
For this experiment, the serial cable is removed from one of the servers for 60
seconds then replaced,
For Windows, the Virtual Shared disk processes were killed and
disabled for 60 seconds.
10) Primary Server public network loss for 60 seconds.
This simulates a loose network cable or a technician error such as a
cable disconnect, card misconfiguration, or a
mistaken command such as ifconfig
en0 down.
For this experiment, the network cable is removed from the MAU for 60 seconds
then replaced.
11) Secondary Server public network loss for 60 seconds.
This simulates a loose network cable or a technician error such as a cable
disconnect, card misconfiguration, or a mistaken
command such as ifconfig
en0 down.
For this experiment the network cable is removed from the MAU for 60 seconds
then replaced.
12) Public network down 60 seconds.
This simulates a power failure on the public hub or MAU, a network storm, or a technican’s error such as a VLAN misconfiguration.
For this experiment, the power cable to the MAU is removed for 60 seconds then
replaced.
13) Private network down 60 seconds.
This simulates a power failure on the private hub or MAU, a network storm or a
technician’s error such as VLAN misconfiguration.
For this experiment, the power cable to the hub is removed for 60 seconds then
replaced.
14) IP address clash public network for 60 seconds.
This simulates a situation where another machine on the same VLAN is
accidentally brought online with an incorrect IP address.
For this experiment, the following command was executed on another machine on
the public network.. ifconfig
tr0 alias 9.16.6.46 netmask 255.255.255.0
then to withdraw the conflicting IP, ifconfig
tr0 delete 9.16.6.46 .
IV Results
During all of the runs, there are plenty of HTTP 206 return codes.
These could be considered either errors or successes. While there is no
significant difference when taking these into account, both sets of results are
shown below. As each trial is ten minutes long, but with an initial full minute
of uptime, one minute’s worth of good data should be removed from each trial’s
results. So 10% of the value of baseline successes has been discarded from the
number of successes for each run. This effectively compares nine minutes of a
trial with clustering to nine minutes of a trial without clustering. Each 10%
(or 0.1 units on the charts below) of uptime represents 54 seconds of availability.
The actual uptime value calculation for the data points in the charts below is: ![]() , where BaselineTrialSuccesses is
the baseline value for either the clustered system or the non-clustered system
as is appropriate.
, where BaselineTrialSuccesses is
the baseline value for either the clustered system or the non-clustered system
as is appropriate.
A sample calculation for cluster versus non-cluster datapoints:
AIX baseline successes without cluster = 4716
AIX baseline successes with cluster = 4645
AIX kill and hold for 30 seconds successes without cluster = 4404
AIX kill and hold for 30 seconds successes with cluster=3873
“NoCluster” Kill and hold for 30 Success value = ![]() = 0.926
= 0.926
“Cluster” Kill and hold for 30
Success value = ![]() = 0.815
= 0.815
AIX HACMP/ES
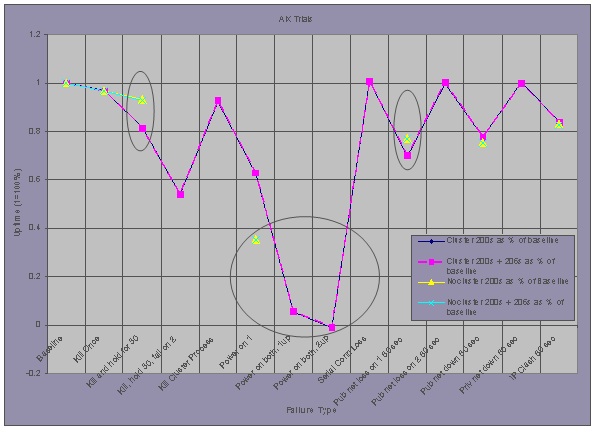
For AIX, the key trials where uptime is higher
(better) for a single server are those trials when public network card/cable
error occurs, “Pub net loss on 1 60 sec,” and
when a short process failure occurs, “Kill and hold for 30.”
In the event of a power failure to the entire environment, in the case where a
cluster is present, the system takes longer to recover and begin serving again
due to startup time for the cluster service and cluster negotiation time. This
is seen by comparing the Power on 1
trial to the two Power on both… trials. The only fault where clustering provided a
significantly better service is during a power failure of the primary node or a
reboot of the primary node, “Power on 1.”
Other notes from the AIX trials:
- For the Kill Cluster Process trial, on the primary node where the process is killed, the act of killing the process hangs the node and manual intervention is required to restart it. Though this does not contribute to downtime, the unexpected ending of the clustering process clearly degrades the state of the cluster.
- The Power on both, 2up trial did recover, but slightly past the 9 minute trial length, the representation above has been adjusted accordingly and the value shown is slightly below zero because the service was actually down for more than 9 minutes.
- During the simultaneous power outage for both the primary and secondary, if the secondary recovers first, it does not assume the resources of the cluster. An effect of this is visible in the difference in uptime between the Power on both, 1up, and Power on both, 2up trials.
- Pub net down 60 secs does not cause a failover.
- IP Clash 60 secs does not cause a failover.
Windows 2000 AS
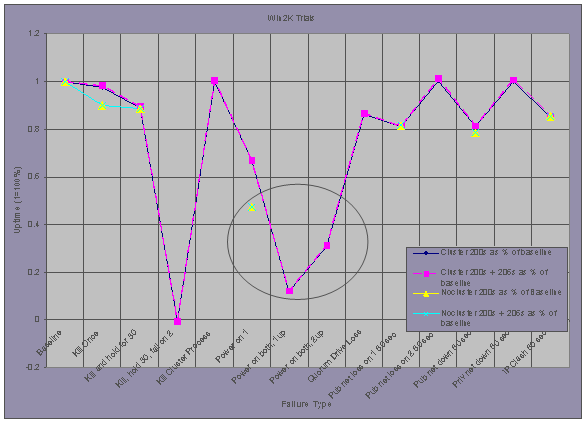
Windows 2000 exhibits one case where the
presence of clustering technology contributes to lower uptime. Similarly to
AIX, in the event of a power failure to the entire environment, in the case
where a cluster is present, the system takes longer to recover and begin
serving again due to startup time for the cluster service and cluster
negotiation time and quorum checking. This is seen by comparing the Power on 1 trial against the two Power on both…
trials. Also, it is somewhat interesting to note that bringing the secondary
node up first after a power failure results in a faster recovery of the service
than does bringing the primary node up first.
Other notes from the Windows 2000 AS trials:
- For the Kill hold30 fail on 2 trial, on the secondary node when the HA process fails to start, the node hangs and is unrecoverable. The primary node never attempts to take back the control of the HA resources, this causes a compete outage until manual intervention occurs.
- The Quorum Drive Loss does cause a failover.
- Pub net down 60 secs does not cause a failover.
- IP Clash 60 secs does not cause a failover.
Red Hat Linux AS with Heartbeat7 and Monit8
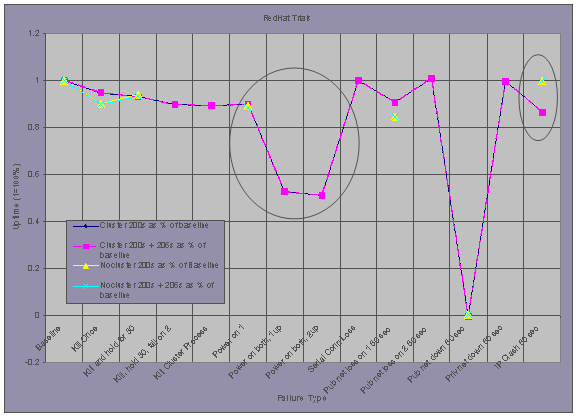
Linux exhibits two cases where the presence
of clustering technology contributes to lower uptime. Similar to AIX and Windows
AS, in the event of a power failure to the entire environment, in the case
where a cluster is present, the system takes longer to recover and begin
serving again due to startup time for the cluster service and cluster
negotiation time. This is seen by comparing the Power on 1
trial against the two Power on both… trials. Also, the 60 Second IP
Clash causes a problem on the cluster while it does not cause one on
the single server. In this case there were many HTTP 404s returned as the ip address ping-ponged between
the cluster nodes. This is possibly due to questionable token-ring support in
Linux.
Other notes from the Red Hat AS trials:
- For the Pub net down 60 sec trial, in both the NoCluster and the Cluster trials, all nodes fail to recover and demand manual intervention. A “hard” reboot is required.
V Other Observations
We find that HA clustering is difficult to configure properly and that the available documentation is lacking in many cases. Once HA clustering is configured properly, it does perform relatively well, but building a HA cluster is similar to certain complex engineering projects such as bridges. Because multiple machines must be configured simultaneously, often packages and software must be installed and configured in specific order, and failure to do so will cause the installation to fail. Often an installation failure requires starting over from the beginning. While it is reasonable to expect that the people installing HA clustering components are technically competent, since the prevalence of HA clustering is recent and each vendor’s implementation is different and has different requisite constructs in the operating system, better models and methods for installation and configuration need to be developed. Youn et al10 suggest that the design of “administration of clusters…needs improvement,” and our research supports that suggestion and extends the definition of “administration” to include initial configuration.
Configuration Comparison
Surprisingly, the simplest HA cluster to configure is the Linux cluster with two independently-produced add-on packages. Some minimal scripting and configuration file editing is required. The Linux clustering solution is the most simple as it will allow installation on one node, then separate installation on the second node. Building a cluster while dealing with the machines’ interdependency is not an issue during installation. Linux HA is easily conceivable as a set of building blocks (monit and heartbeat) that perform specific tasks and their interdependency is well-documented.
Configuring an AIX HA cluster requires knowledge of many concepts specific to AIX clustering and for us, required the most retries during the configuration process. AIX will not allow HA clustering to be installed on one node at a time; instead, it requires both nodes to be configured properly, simultaneously. Minimal scripting to make sure that httpd is running is required for AIX.
Windows, as Microsoft claims1, requires absolutely no scripting and configuration is drag-and-drop. Windows will allow installation on one node, then the joining of the second node to the cluster. Microsoft also understands the frustration of System Administrators and is working to make things better for them. Vogels et al,13 speaking generally about cluster technology, state, “Users find it difficult to configure clusters with the desired management and security properties. It is difficult to configure applications to be automatically launched in an appropriate order, to deal with wide-area integration issues, and otherwise to match the cluster to application needs. Lacking solutions to these problems, clusters will remain awkward and time-consuming tools.” Their design of MSCS does obviously strive to fix this configuration issue.
These observations need to be tempered with the fact that the AIX and Windows clustering systems handle many different types of faults and provide more options for requisite aspects to failover than the Linux System, though these features are not used in this study. Linux, in typical Linux style, lets the customer decide on the minimal features needed and makes very few assumptions, while the other two systems provide many features yet make some limiting assumptions about networks and hardware. In any inter-OS comparison though the predicted stability of the OS must be taken into account; for example, in at least one trial, both the Windows 2000 cluster and the Linux cluster ended up in a state with both machines simultaneously requiring manual interventions, while the AIX cluster never entered that state.
VI Conclusion and Limitations
To a system designer or architect, HA clustering is a reasonable option to increase uptime in an environment with expected failures/faults, but the types of failures expected must be taken into account. If system-wide power outages are the most common failure, then clustering is shown to actually decrease the uptime of a service or site. If Byzantine application failures are most common and a mere restart of the HA process will restore the service, then HA may be appropriate. If rolling upgrades are required, HA may be appropriate but less costly and less interdependent solutions probably exist. If a large amount of human error or configuration error is expected, then HA may be appropriate. The high failover times for some systems (more than 30 seconds in many cases) contribute to a lower-than-expected performance of HA systems when compared to non-HA systems. Zhou, Chen and Li3 point out that more than 10 seconds should be considered unacceptable for mission-critical applications. Fault detection must be accurate, failover time must be quick, and primary node elections must be quick too. Failover times need to be significantly smaller than the time required for a reboot or even a restart of a slow-to-start process; this is illustrated by the Linux results because a reboot and a failover are almost the same length in time.
Noting how close the “NoCluster” data points and the “Cluster” data points are on the graphs above, the value added by the inclusion of HA clustering in an environment is questionable in many cases given its associated costs. HA is not a perfect solution for every requirement, and may be a bad solution for some. Like many tools, its effects need to be understood prior to the application of it to a situation.