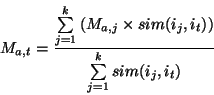
Here, ![]() denotes the prediction value of target user
denotes the prediction value of target user ![]() on target item
on target item ![]() . Only the
. Only the ![]() most similar items (
most similar items (![]() nearest neighbors of item
nearest neighbors of item ![]() ) are used to generate the prediction. Despite their effectiveness, item-based CF algorithms still suffer from the problems associated with data sparsity, and they still lack the ability to provide recommendations or predictions for new or recently added items. To deal with these problems, we introduce an approach for semantically enhanced collaborative filtering in which structured semantic knowledge about items, extracted automatically from the Web, is used in conjunction with user-item ratings (or weights) to create a combined similarity measure for item comparisons. This approach is discussed in the next section.
) are used to generate the prediction. Despite their effectiveness, item-based CF algorithms still suffer from the problems associated with data sparsity, and they still lack the ability to provide recommendations or predictions for new or recently added items. To deal with these problems, we introduce an approach for semantically enhanced collaborative filtering in which structured semantic knowledge about items, extracted automatically from the Web, is used in conjunction with user-item ratings (or weights) to create a combined similarity measure for item comparisons. This approach is discussed in the next section.