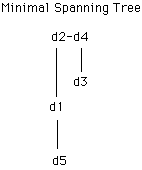Clustering can be derived from the MST, which is built by successively connecting the next document that is closest to any of documents already clustered.