Intelligent
Information
Retrieval
CSC 575
Assignment 2
Due: Sunday, February 05,
2023
General Notes: for all programming assignments, please provide
your clearly documented code and clearly labeled outputs. Presentation clarity,
as well as code documentation, modularity, and efficiency will be used as
criteria in the evaluation of assignments.
If you are submitting Jupyter Notebooks, please submit both the source file
(IPYNB) as well as the HTML version of your Notebook.
- [35 pts] Collocations and Mutual Information
Write a program to compute the pairwise mutual information measure for word
pairs
appearing in a document corpus. Start by writing a function
co-occurrence(corpus,
window_size) which takes as input the document corpus and a token window size (to
be used to estimate co-occurrence frequencies) and returns frequency values for
word pairs as well as for individual words. For simplicity, you can assume that the
document corpus is comprised of a single document with partially preprocessed
tokens separated by white-space (see the test corpus provided below as an
example). Then using the frequency information, compute and display the mutual
information measure as discussed in the lecture notes:
Content Analysis & Statistical Properties of Text.
Your clearly formatted output should include word pairs in decreasing order of
I(x,y) (mutual information for words x and
y). along with the frequencies words and the co-occurrence (see
example below for sample output).
To estimate the frequency values you
should implement the window-based algorithm presented in the lecture notes. In
this algorithm, overlapping windows of size window_size are
generated with the window advancing by a single token in each iteration (thus
generating ngrams of size window_size). Note that this process
will result in a total of N_w = N - window_size + 1
overlapping windows, where N is the totla number of
tokens in the corpus. For a pair of word (x, y), the frequency
of co-occurrence of x and y, f(x,y),
is estimated as the number of windows in which the x and
y co-occur. Note that the order in which x and
y appear in each window is not relevant, and within each window only
one co-occurrence of x and y contributes to
the frequency, f(x,y). For individual words, f(x)
and f(y) are taken to be number of occurrences of x
and y in the whole corpus, respectively. These frequency values
are divided by N to estimate probabilities
P(x), P(y), and P(x,y) used in
computing the pairwise mutual information, I(x,y).
As an
example, consider the sample document corpus containing 14 tokens:
['search queri process retriev process queri relev feedback
queri relev process queri process queri']
Using window_size = 3, there will be 12 overlapping
windows:
token window 1 = ['search', 'queri', 'process']
token window 2 = ['queri', 'process', 'retriev']
token window 3 = ['process', 'retriev', 'process']
token window 4 = ['retriev', 'process', 'queri']
token window 5 = ['process', 'queri', 'relev']
token window 6 = ['queri', 'relev', 'feedback']
token window 7 = ['relev', 'feedback', 'queri']
token window 8 = ['feedback', 'queri', 'relev']
token window 9 = ['queri', 'relev', 'process']
token window 10 = ['relev', 'process', 'queri']
token window 11 = ['process', 'queri', 'process']
token window 12 = ['queri', 'process', 'queri']
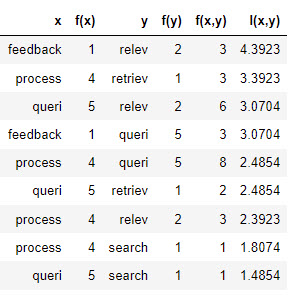
This will result in the following frequency values:


The final output including the mutual
information values for this example is depicted in this
table.
Test your program using the test document corpus:
hw3-test-corpus.txt using window sizes 2 and 3
and in each case provide the final output including the frequency and mutual
information values as suggested above.
- [35 pts] Indexing Models and Term Weighting
Consider a term-by-document matrix (with M terms as rowa and N documents as
columns) with entries corresponding to raw terms counts. Write a program (or programs) to perform each of the following tasks according to
the specified indexing models (term weighting schemes). Your program should
work for any number of terms and documents. However, you should test and
demonstrate your
program with the term-by-document matrix provided in the file:
hw2-term-doc-matrix.csv. You may use
standard numeric or data manipulation libraries for the language of your
choice (e.g., Numpy or Pandas in Python). However, you should not use
built-in functions that directly perform the specified task (e.g.,
tf x idf transformation).
- Convert raw term counts to (non-normalized)
tf x idf weights. Use log base 2 in computing the IDF
values for each term. Note: you should not use any
libraries or built-in functions that directly compute tf x idf values. Provide the
resulting document-term matrix with the new weights as final output. As
intermediate result, output the IDF values for each term as a single
list or table..
- Compute the new weights using the
signal-to-noise ratio approach.
Again use log base 2 in your computations. In addition to the final
term-document matrix with new signal-based weights, provide the a list
of entropy (Avg-Info) values for each term.
- Using the Term Discrimination model compute and
display the discriminant value for each term in the vocabulary. You may
wish to start by creating a function to take a specific term and the
term-doc matrix as inputs and display the discriminant value for the
term as output. Along with the discriminant value for each term, output
the average similarity across documents with that term omitted. Use this
function to iterate overall terms and output the results. Based on your
results identify the most and the list discriminating terms in the
vocabulary. Note: to compute average
similarities use Cosine similarity as your similarity measure. Write your
own Cosine similarity function by computing the normalized dot product
of two vectors.
- [20 pts] Vector-Space Retrieval Models
Given a N x M document-term matrix (containing raw term
counts), and a query Q, write a program (or programs) to compute
query-document similarities, using different similarity measures, and
display the list of documents along with their scores in each case.
Specifically, your program(s) should compute query-document similarities
using each of the following similarity measures:
- Dot product
- Cosine similarity
- Dice's coefficient
- Jaccard's coefficient
You may assume that the query Q is a M-dimensional vector (similar to
rows in the matrix representing document vectors). Do not use external
libraries that directly compute these similarities; you'll need to write
your own similarity functions. However, as noted before, you may use
numeric or data manipulation libraries such as Numpy and Pandas to
perform basic array/matrix maipulation. You may wish to write separate similarity
functions for each measure computing the similarity between two
individual vectors. Your program can then iterate over documents (rows
in the matrix) and compute similarity between each document and a given
test query vector. Ideally, you should pass the similarity function as a
parameter to your larger program/function to avoid code repetition.
To test your program, use (the transpose of) the same term-document
matrix given in the previous problem: hw2-term-doc-matrix.csv. As the test query use the following query
vector:
Query Q = [3, 1, 1, 0, 2, 0, 3, 0, 2, 0, 1, 2, 0, 0, 1]
Your output should include lists of documents and their similarities to
the query for each of the aforementioned similarity
measures. Please clearly identify which list corresponds to which similarity
measure.
-
[10 pts] [Non-Programming Assignment] Positional Indexes and Phrase Queries
Shown below is a portion of a positional index in the format:
term: doc1: [position1, position2, ...]; doc2: [position1,
position2, ...]; etc.
angels: 2: [36,174,252,651]; 4: [12,22,102,432]; 7: [17];
fools: 2: [1,17,74,222]; 4: [8,78,108,458]; 7: [3,13,23,193];
fear: 2: [87,704,722,901]; 4: [13,43,113,433]; 7: [18,328,528];
in: 2: [3,37,76,444,851]; 4: [10,20,110,470,500]; 7: [5,15,25,195];
rush: 2: [2,66,194,321,702]; 4: [9,69,149,429,569]; 7: [4,14,404];
to: 2: [47,86,234,999]; 4: [14,24,774,944]; 7: [199,319,599,709];
tread: 2: [57,94,333]; 4: [15,35,155]; 7: [20,320];
where: 2: [67,124,393,1001]; 4: [11,41,101,421,431]; 7: [16,36,736];
Which document(s) if any match each of the following queries,
where each expression within quotes is a phrase query (briefly explain your
answes)?
- “fools rush
in”
- “fools rush in” AND “angels fear to tread”
Back to Assignments
|

{kind=link}