Intelligent
Information
Retrieval
CSC 575
Assignment 1
Due: Sunday, January 22, 2023
- [25 pts] IR Evaluation
Suppose that we have a standard IR evaluation data set containing
a set of 1,000 test documents, a set of test queries, and relevance
judgements on query-document pairs. Assume that a particular query, Q, in this data set is deemed to be
relevant to the following 20 documents in the collection:
REL = { d1, d5, d10, d88, d150, d200, d210, d250, d300, d400, d405,
d472,
d500, d501, d545, d600, d635, d700, d720, d800}
Two different retrieval systems S1 and S2 are used to retrieve ranked lists
of documents from this collection using the above query. The top 10 retrieved
documents for these two systems are given below (each list is in decreasing
order of relevance).
RET(S1, Q) = d1,d200,d150,d4,d10,d400,d88,d600,d500,d520
RET(S2, Q) =
d400,d33,d150,d117,d999,d101,d501,d800,d15,d88
This information is provided in the following CSV files for your
convenience:
hw1-relevant.csv - test
documents relevant to query Q and their relevance weight (or gain). The gain
is only used for part c below.
hw1-retrieved.csv - Top
10 document retrieved by S1 and S2, respectively, ranked in decreasing order
of relevance.
[Note: for this problem you do not need to write a
program (though you can if you wish). At minimum, you should consider using
a spreadsheet program (such as Microsoft Excel) to facilitate performing the
computations and visualization. You should submit your
spreadsheet or program, and the answers to the following questions clearly
identified.
- Compute the Precision and the Recall graphs for each system as a
function of the number of documents returned (for 1 document returned, 2
documents returned, etc.). First, compile your calculations in a table which
shows the Precision and Recall for S1 and S2 as a
function of the number of documents returned (from 1 to 10). Then, create separate graphs for Precision
and Recall, in each case comparing the two systems. For each graph, use the
number of retrieved docs (from 1 to 10) as the x-axis and the value of the
metric (precision or recall) as the y-axis.
- A single metric that can be used to combine precision and recall is the
F Measure (see Section 8.3 of the IR Book). Using the F measure with B=0.5
(equation 8.5), create a graph similar to the above
comparing the two systems.
- Next, using the graded relevance weights (gain) provided
for the relevant documents, compute the Discounted Cumulative Gain
(DCG) and the Normalized DSG (NDCG) values for the retrieved documents for
both S1 and S2. Depict the results in a graph similar to previous parts
comparing NDCG for S1 and S2.
- [40 pts] Inverted Indexes
Write a program to create a
simple inverted index from a set of text documents and to generate the
outputs specified below.
Recall that an
inverted index contains two components: a dictionary containing all unique
tokens (not including stop words) in lexicographic order, and a set of
postings that for each token contain a list of document ids in which the
token appears along with its occurrence count in each document
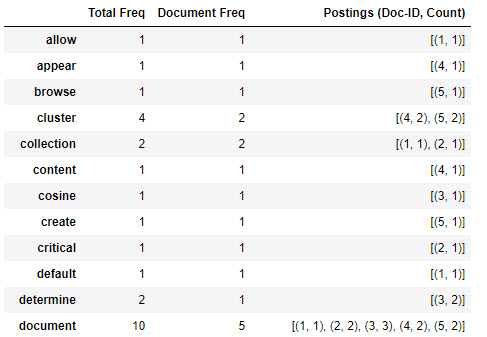
(conceptually, an inverted index might look similar to this example).
Note that the dictionary also contains (for each term) statistics such as
total number of occurrences in the collection and the document frequency
(number of documents in which term appears).
Your program should take a set of documents
as input, parse each document to identify tokens (tokenization), convert
tokens to lower case, and remove
punctuation symbols and stop words. You may assume that tokens are alpha-numeric
strings separated by white space (after removing punctuation symbols). You
must use the following list of stop words:
stopwords_en.txt. You
do not need to perform stemming
for this problem (for the provided test data some minimal and rudimentary
stemming has already been performed). Your program should first construct an
inverted index using an appropriate data structure. While there are various efficient data structures in
which to store the dictionary, in this case you may consider using a
hashtable (such as a Python dictionary or Java Hashmap) with tokens as keys.
Similarly, a hashtable can be used to store the posting lists for each
token.
Once the inverted index is constructed, your program should
allow the user to input a token that's part of the
vocabulary and return the list of documents in
which the token appears along with the occurrence counts for the token in
each document.
Test your program on
this small set of test documents
provided (each document is a line preceded by the document ID). Submit
the following along with your well-documented code.
- Show the full contents of the dictionary in lexicographic order of
tokens along with document frequencies and total frequencies in an
easily readable format (see this
example of what a partial output might look like). In your
submission, clearly show the execution of your program and the output
generated.
- Show the output of your program when
searching the postings for these individual tokens: "index", "cluster", "query",
"search", "engine", and "retrieve" (in each case the output should show
the "hit list" of documents containing the token along with the token's
occurrence count in each document. In your submission, clearly show the
execution of your program and the output generated.
- Based on the results obtained in
part b show the set of documents resulting from the following Boolean queries (you
need not implement a query mechanism; you only need to give the end
result for each query):
- index AND query
- index OR query
- index AND (NOT
query)
- (search AND query) OR (search
AND retrieve)
- (index OR cluster) AND (engine
OR search)
- [25 pts] Character Ngrams to Find Similar Terms
Write a program/function to compute the (syntactic) similarity between two
words using character ngrams with Dice's coefficient used to compute the
similarity score [See slides 36-37 in Week 2 lecture:
Indexing and Document Analysis). Your function,
ngram_sim(word1, word2, N),
should take as input two
words and the value of N (the length of ngrams) and return the similarity
score between the two words. As intermediate output, your function should
also display the number of unique ngrams for each word and the number of
unique shared ngrams between the two words. Test your function on the words
"statistical" and "statistics" with N=2 (for bigrams) as shown in the
lecture slides. [As an example, here is a
sample output for N=2 and N=3].
Next using N = 2
and N = 3, compute similarities between the word "promotional"
and each of the words:
- proportion
-
proportional
-
promotion
-
emotional
In each case provide the intermediate outputs of your program specified
above as well as the final similarity score.
- [10 pts] WordNet
WordNet is an advanced lexical ontology and
thesaurus for the English language with many applications in information retrieval and
natural language processing. Write a one page document about WordNet containing the following elements: (1) Your own description
of WordNet; (2) a summry of the unique features of WordNet that distinguish it from other types of standard
thesauri; and (3) a discussion of ways WordNet can be (or has been) used in
the context of information retrieval.
Back to Assignments
|

{kind=link}
{kind=link}
{kind=link}