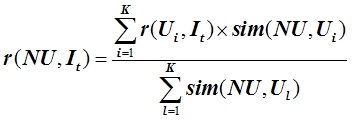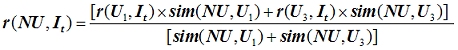User-Based Collaborative Filtering with K-NNHow to compute Predictions: Suppose that we have a new target user NU and we want to compute the predicted rating for NU on a target item It (an item NU has not rated). Assume that we have identified the K nearest neighbors, U1, U2, ..., Uk for NU (generally, by computing the correlaton between rating vectors of user NU and all users in the training database and then ranking the top K most similar/correlated users to NU in decreasing order of similarity). Let us denote the rating given by user Ui to an item Ij by r(Ui,Ij). Also, let us denote the similarity of user Ui to user NU as by sim(NU, Ui). Note that, generally, this similarity is computed as the Pearson correlation of the two users. Using the weighted average approach, the predicted rating of NU on the target item It can be computed as follows:
In other words, the ratings of the K neighbors are weighted by their similarity (correlation) to the target user, and the sum of all these weighted ratings is divided by the sum of all the similarities across the K neighbors. Important Notes:
|