 |
Craig S. Miller
School of Computer Science
DePaul University
Chicago, IL USA
cmiller@cs.depaul.edu
Roger W. Remington
NASA Ames Research Center
Moffet Field, CA USA
rremington@mail.arc.nasa.gov
We describe a computational model of Web navigation that simulates a user searching a Web site for a specified target item located under one of the site's terminal links. Though the model implements a simple user strategy it produces results that are consistent with published empirical studies that show longer search times for a three-level site than for comparable two-level sites. Despite its simplicity, it demonstrates complex interactions between site depth and the quality of Web link labels and predicts that, as the quality of link labels diminish, the advantage for flatter Web structures increases.
The identification of factors that affect the usability of the World Wide Web has become increasingly important as the Web continues to revolutionize how people obtain information, buy products, and conduct business transactions. Companies find it increasingly important to design a Web site that customers can easily navigate to find information or products. In keeping with this growth, there seems to be no shortage of advice on how to design effective, navigable Web pages [Byrne et al., 1999,Spool et al., 1999,Tiller & Green, 1999]. Much of this advice is based on common sense or anecdotal experience rather than systematic study. Empirical observations often lack important methodological detail. Only recently has there been an effort to establish design guidelines based on rigorous empirical studies. For example, Byrne et al.(1999) developed a taxonomy of Web actions based on observed user behavior from which they were able to compute the frequency of different classes of behavior. Larson and Czerwinski (1998) examined user search times in Web pages of differing hierarchical depth. They found that flat structures, with as many as 32 links to a page, produced faster search time than deep hierarchical structures.
The Larson and Czerwinski results appear to be at odds with theory and empirical results of studies of hierarchical menu design (see Norman, 1991 for a review). An information theoretic analysis of hierarchical structures suggests that the optimal number of selections per page ranges from 4 to 13, assuming a linear self-terminating search in each page and a reasonable range of reading and key-press times [Lee & MacGregor, 1985]. This analysis is far less than the 16 to 32 suggested by Larson and Czerwinski. Empirical results of menu search experiments are broadly consistent with this analysis. Structures with as many as 8 selections per page produce faster search results than deeper structures with fewer selections per page [Miller, 1981,Snowberry et al., 1983,Kiger, 1984]; broader structures with significantly more than 8 selections per page produce slower search times [Miller, 1981,Snowberry et al., 1983,Kiger, 1984] unless the pages have naturally organized selections in numeric or alphabetical order [Landauer & Nachbar, 1985] or were naturally grouped in categories [Snowberry et al., 1983]. Since the labels for the selections in Larson and Czerwinski were not grouped or ordered, we need an alternate explanation to account for the success of the extremely broad Web structures (i.e. 16 to 32 selections per page) in that study.
In this paper, we provide an explanation for this discrepancy through the use of a working computational model. This model simulates a user navigating through a Web site making choices about whether to select a given link or evaluate an alternate link on the same page. With a few simple assumptions about search strategy and time cost, the model provides a deeper explanation of the factors that influence Web page search times that resolves the conflict between Larson and Czerwinski and previous menu studies.
By introducing and applying a model of Web navigation, we also aim to demonstrate the viability and utility of modeling Web usage in general. The results of empirical studies, though essential, can be influenced by context-specific factors making it difficult to generalize to situations other than those tested. In addition, empirical testing is too expensive and time consuming to address the wide range of content, configurations, and user strategies that characterize the Web. A cognitive model that describes the underlying processes that produce behavior provides the means to generalize empirical results. By constructing the model so that it is functionally sufficient and uses plausible cognitive mechanisms, we obtain a working, explicit hypothesis of user interaction, which can be further tested by comparing its behavior to known empirical results. For example, Peck and John (1992) used a computational model to highlight patterns of interactions with a browser. More recently, Lynch, Palmiter and Tilt (1999) describe a model that interacts with a Web site and reports on the accessibility of the site's content. Once the cognitive model has been implemented and tested, it provides the added advantage of quickly and easily testing a large variety of Web sites under different conditions.
Our model interacts with a simplified, abstract representation of a Web browser and a Web site. Following Larson and Czerwinski (1998), we restrict our Web sites to structures that are balanced trees. Each site has one root node (i.e. the top page), consisting of a list of labeled links. Each of these links leads to a separate child page. For a shallow, one-level site, these child pages are terminal nodes, one of which contains the target information that the user is seeking. For deeper, multi-level sites, a child page may consist of a list of links, each leading to child pages at the next level. The bottom level of all our sites consists exclusively of terminal pages, one of which is the target page.
When navigating through a site, a user must perceive link labels and gauge their relevance to the sought-after information. While the evaluation of a link is a complex and interesting process in itself, we choose not to model the process per se. Rather, our interest involves the consequences of different levels of perceived relevancy. As a proxy for each link label, we fix a number, which represents the user's immediately perceived likelihood that the target will be found by pursuing this link.
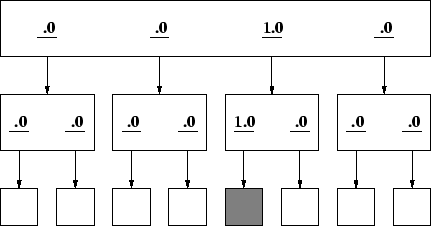
In an ideal situation, the user reads each link label and knows with certainty which link to select and pursue. Figure 1 represents such a site. The rectangles represent Web pages. The underlined numbers represent links to child and parent pages. The top page for this site contains four links where the third link, labeled with a 1, eventually leads to the targeted page. Of the eight terminal pages, the page represented by the filled rectangle contains the target information. In our terminology, this example site has a 4x2 architecture, where 4 is the number of links at the top-level and 2 is the number of links on each child page. For this site, the user need only follow the links labeled with a 1 to find the targeted page with no backtracking.
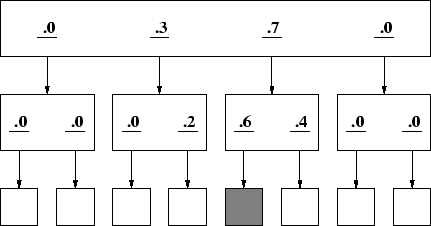
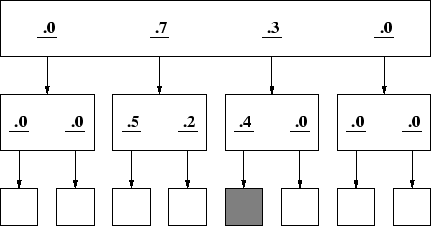
Figure 2 shows an example of a simple two-level site with links whose relevance to the target is less certain. The top page in this figure contains four links labeled with numerical likelihood factors of .0, .3, .7 and .0 that represent the user's belief that the path associated with a given link contains the target information. As before, a user strategy that merely followed the most likely links would directly lead to the target. However, Figure 3 shows the same site with a different user for whom the meaning of the labels differ from the user in Figure 1. This user would find the target under what he or she perceives as a less plausible sequence of link selections. In this way it is possible to represent sites that differ widely in strength of association between link label and target information - from virtual certainty (links of 1.0) to complete uncertainty.
Byrne et al. (1999) found that selecting a link and pressing the Back button accounted for over 80% of the actions used for going to a new page. Consequently, we focused our modeling on the component actions underlying these behaviors. These include:
All four are primitive actions that our model performs serially. Fixed times are assigned to each action to account for their duration during a simulation. Our model also simulates changing the color of a link when it is selected so that the modeled user can ``perceive'' whether the page under this link was previously visited.
These four primitive actions can be combined to create a simple yet plausible model of a user navigating a Web site attempting to find target information located on one page. The strategy is described in pseudocode below:
attend to new page*
check for target
if target
terminate (successful)
else
for each unvisited link (starting at last selected link)
determine if link is above threshold (relevant) *
if link is relevant
select link * and reset strategy
//comment -- now all links on this page have been checked
if at root page
if threshold has already been reduced
terminate (unsuccessful) task
else
reduce threshold to secondary value (i.e. .1)
else
press Back button* and reset strategy
|
The model's behavior on the site presented in Figure 3 can be illustrated by the following trace:
Attend to page Link (.0) is evaluated, below threshold Link (.7) is evaluated, above threshold Link (.7) is selected (new page appears) Attend to page Link (.5) is evaluated, above threshold Link (.5) is selected Attend to page -- no target present Press Back Button Attend to page Link (.2) is evaluated, below threshold Press Back Button (no remaining unexamined links) Attend to page Link (.3) is evaluated, below threshold Link (.0) is evaluated, below threshold (threshold is reduced to .1) Attend to page Link (.0) [first link] is evaluated, below threshold (link (.7) is skipped; it is already examined) Link (.3) is evaluated, above threshold (.1) Link (.3) is selected (new page appears) Attend to page Link (.5) is evaluated, above threshold Link (.5) is selected (new page appears) Attend to page -- target is present
Several points are worth noting. First, only the items with an asterisk incur a time cost that adds to the cumulative simulation time. Second, the threshold for traversing a link is reduced (by .1 in the current simulation) only when there are no unselected links above threshold in the root page. Third, in this strategy, the model does not search down links it has already examined even when the threshold is reduced. As a result it does not exhaustively search the Web site and can miss targets whose path contains a parent with a below threshold link relevance.
We can calculate a simulated search time by assuming plausible time values for attending to a page, evaluating a link, selecting a link, and for pushing the Back button. The above trace shows that attending to a new page occurred 8 times, evaluating a link occurred 9 times, selecting a link 4 times, and pushing the Back button 2 times. For now, we assume that evaluating a link requires a half second and the remaining events require one second. For this example, the total simulated time is 18.5 seconds (8 + .5 * 9 + 4 + 2). Interestingly, had the target been in the terminal Link (.2), under the top-level Link (.7) the strategy would fail to find it. The Link (.2) was examined under the high threshold (.5). When the threshold is later reduced, this link is ``hidden'' because its parent Link (.7) had been previously selected. We will later see that this situation accounts for a significant portion of search failures as it demonstrates a pitfall of deep-structured architectures.
In our trace, we see that the action of attending to a page generally follows a ``select'' action or a ``back'' action. It is useful to approximate these two actions with a single estimate of 2 seconds. Applying this approximation to the above example yields a new total of 16.5 (.5 * 9 + 4 * 2 + 2 * 2) instead of 18.5 seconds. The difference of two seconds becomes even less significant when modeling navigation through larger sites.
While the actual practice of Web navigation is certainly varied and complex, the threshold strategy has at least three general qualities that make it a reasonable approximation of actual Web navigation. First, it successfully finds the target whenever it lies behind likely links. Second, by skipping less likely links, it finds the target quickly, again provided that the target is behind likely links. Finally, it places few cognitive demands on the user. Instead of using memory to store previously explored links and pages it uses the browser's record of visited links to indicate what has been explored.
Our first goal is to determine reasonable time costs for the model's primitive actions from which we can explain and predict qualitative trends. Research in menu selection has proposed and justified a reasonable range of time costs [Lee & MacGregor, 1985]. Miller (1981) reported that humans searching through an 8x8 menu system took slightly less than three seconds on average [Miller, 1981]. Because selection errors occurred less than 1% of the time, we conclude that the system's selection labels were accurate, clear and unambiguous. We simulated Miller by creating a model of an 8x8 site with clear, unambiguous labels. Nodes that led to the target were given a relevance factor of 1, others were given a relevance factor of 0. Since no backtracking occurs, there are only two timing costs that need to be established: evaluating a link label and selecting a link (recall that selecting a link includes the time to display and to start examining the next page).
Using ranges of costs from 250ms to 750ms at increments of 250ms, we ran simulations to find out which combinations produce a good match to Miller's result of slightly less than 3 seconds. Table 1 shows simulation times averaged over 10,000 runs each. The cost settings closest to the Miller result were 250ms for link evaluation and 500ms for link select, which produced a total search time of 2.9 seconds. Settings of 250/250 and 250/750 produced total search times of 2.4 seconds and 3.4 seconds, respectively, which is also close to the 8x8 total time reported by Miller. Other cost settings were significantly further away from the Miller result.
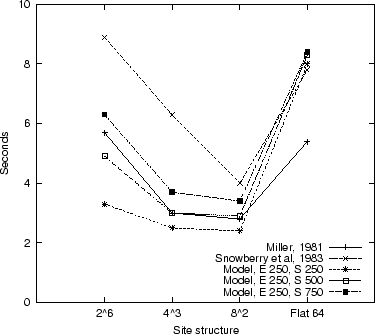
We then took the three best-fitting cost settings on the 8x8 comparison and
evaluated their performance on other structures tested by Miller. These
alternate structures include 2x2x2x2x2x2 (![]() ), 4x4x4 (
), 4x4x4 (![]() ) and a flat
structure of 64 selections. We also compare our results to those presented by
Snowberry, who also ran studies on menu systems with these same structures.
) and a flat
structure of 64 selections. We also compare our results to those presented by
Snowberry, who also ran studies on menu systems with these same structures.
The results of our comparisons are shown in Figure 4. The results for Miller, Snowberry and the three models all show the same qualitative pattern, namely that the 8x8 structure produces the fastest search times compared to the other structures. As for absolute times, the parameter values of 250/500 model matched the Miller data the closest and will thus be used in the remainder of the simulations.
When comparing our model to the Miller and Snowberry results, we were assuming that the model was running under ideal links. That is, the model need only follow a `1' to successfully find its target page without any backtracking. Here we present a systematic way for introducing label ambiguity to our simulated site.
To assign likelihood factors to the links, we perturb the ideal link values (1, 0) with noise according to the formula below:
g * n + v
In this formula, g is a number chosen randomly from a standard normal distribution (mean=0, stdev=1); n is the noise factor multiplier (equivalent to increasing the variance of the normal distribution); and v is the original likelihood value (0 or 1). Since this formula occasionally produces a number outside the range from zero to one, our algorithm may repeatedly invoke the formula for a link until it generates a number in this range.
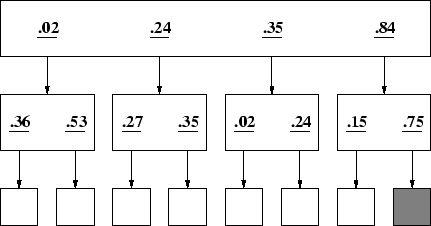
Figure 5 shows a 4x2 architecture n = .3 that was used in our simulation. This procedure also generated atypical representations in which the target was not associated with the highest valued link.
For our simulations, we created representations of the three architectures used in Larson and Czerwinski: 8x8x8, 16x32, and 32x16. For each generated site representation, we randomly placed the target at one of the site's terminal pages and then crossed each structure with a range of noise parameters (0.0 through 0.5). For each pairing, 10,000 times trials were run, each of which used a newly generated site representation.
For simplicity we set the time parameter for pressing the Back button at the same 500 milliseconds used to select a link. The present simulation thus ignores caching, which could substantially reduce the time for Back selections. Following the Larson and Czerwinski study, any trial lasting longer than 5 minutes (300 seconds) of simulated time was terminated and labeled as a failed search.
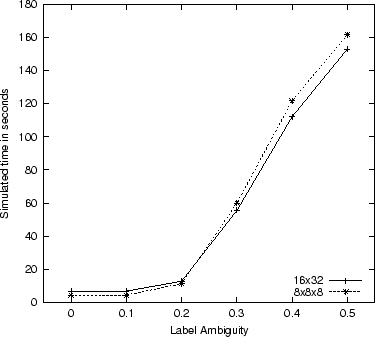
Following Larson and Czerwinski, we encoded failed attempts as taking 300 seconds (5 minutes) when calculating mean times. All mean times had a 95 percent confidence interval of plus or minus 2.5 seconds or smaller. Because the performances on the 32x16 and 16x32 architectures were nearly identical, we only display the 16x32 here. Figure 6 shows the calculated mean times from the simulation conditions. The most salient trend is that link noise had a profound detrimental effect on search time. Comparing the search times of the two architectures, we see that the 8x8x8 structure produced slower search times than the 16x32 structure once the label ambiguity exceeded 0.3. Until that point, however, the two structures produce similar times with the 8x8x8 structure producing slightly faster times than the 16x32.
With a sufficient level of label ambiguity, our simulations produced results consistent with the Larson and Czerwinski results. Namely, with a label ambiguity level of 0.3 or greater, the deeper 8x8x8 structure produced slower search times than the more shallow 16x32 and 32x16 structures. At the same time, with little to no label ambiguity, our simulations produced the opposite results, where the deeper 8x8x8 structure produced slightly faster search times than the more shallow structures.
This pattern of results suggests that the discrepancy between the results from menu selection and the results from Larson and Czerwinksi can be explained by differences in label ambiguity. Specifically, our model predicts that the link labels in Larson and Czerwinski were more ambiguous than those of the earlier menu studies. We are at present working on an independent means of assessing link label relatedness.
Our simulations revealed an interaction between the factors underlying search in Web pages that has been previously ignored in advice on Web page design. This suggests that general design principles may be too simplistic to be applied across the board. Instead, we argue that continued model-based simulation should be focused at more complex architectures that better characterize the link structures in Web pages. Such model-based simulations provide a means of exploring factor interactions that more accurately capture Web usage characteristics.
Perhaps the most immediate and practical consequences of our study is that results from menu selection research are consistent with what we know for Web pages. In particular, when the link labels are relatively clear, Web pages constructed with 8 links per page produce efficient search structures when compared to more shallow structures whose pages consist of significantly more links (i.e. 16 links per page). However, our study also reveals that shallow structures, whose pages consist of more links, become increasingly more effective as the quality of link labels diminish.